The journey of cloud infrastructure costs for enterprise-scale data lakes over the past half-decade has been nothing short of dramatic. Back in 2020 the “curves crossed” and cloud IT spending surpassed data center spending. Total cloud IT costs have already surpassed $200B and they are still going strong.
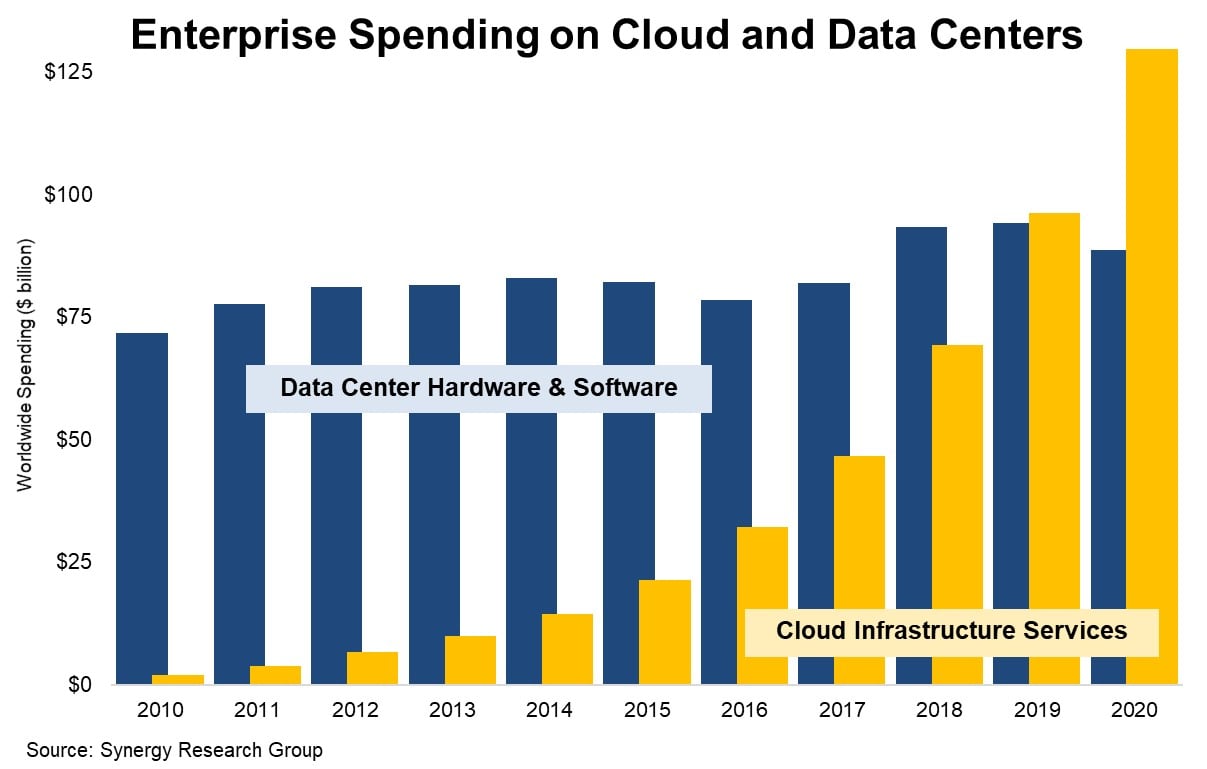
Source: Synergy Research Group
Not surprisingly, the costs associated with data lakes are a significant portion of that overall cloud infrastructure spending.

Initially, the cloud promised a cost-effective, scalable solution for data lake storage and analytics. However, as data volumes have exploded and the complexity of analytics has increased, costs have followed an upward trajectory. This trend is partly due to the sheer volume of data being processed and stored, and partly because of the increasing sophistication of the tools and technologies used to derive insights from this data.
When we think about the types of data in a cloud data lake and what that data is used for, it is increasingly about ML and AI. AI is hungry not only for compute (especially expensive GPUs) but also for data, as larger (and higher quality) training data sets have been shown to improve the accuracy and effectiveness of AI more than tweaking and fine tuning models themselves. Taken together, it isn’t surprising that nearly half of organizations with a large cloud spend are seeing a rapid rise in the all-in costs of AI/ML, and they are turning their attention to manage those costs using FinOps practices.

Breaking down the data Lake
Let’s step through the biggest sources of cost for a cloud data lake, and highlight how growth in data is driving many of them:
- Storage Costs: This is typically the most significant cost, as data lakes store vast amounts of structured and unstructured data. The cost varies based on the amount of data stored, the type of storage (e.g., hot, cool, or cold), and the storage class (e.g., object storage, block storage). Frequent access and retrieval can also increase costs. Modern cloud data lakes are built on object storage as it can handle any file type, including internally structured files heavily used in analytics and AI such as Parquet, Avro, and ORC. To date, not much could be done to address at-rest costs here outside of tiering (hint: there is a better way - but I digress). To put data costs in context, imagine an enterprise data lake with 10PB of data in the Standard class of object storage. At list prices, that 10PB costs ~$220k/month, or ~$2.6M/year.
- Compute Costs: Data lakes require substantial computing resources to process and analyze the stored data, typically via distributed platforms like Apache Spark, and more data means higher compute costs. This includes the cost of running virtual machines, containers, or serverless functions for tasks like ETL (extract, transform, load) operations, data analysis, and machine learning model training.
- Data Transfer Costs: Transferring data out of the cloud data lake can incur costs, for example when transferring (or replicating) between regions for access to GPU/CPU compute, for compliance, or for disaster recovery. Note also that these costs tend to scale with the underlying data volumes.
- Networking Costs: Networking costs include the charges for internal and external network traffic, VPN connections, and dedicated network lines (e.g., AWS Direct Connect, Azure ExpressRoute). These costs are associated with the bandwidth and the amount of data transferred over the network - and once again these costs scale with data.
- Backup and Recovery Costs: Ensuring data durability and business continuity through backups and disaster recovery strategies can also contribute to the overall cost. This involves (you guessed it) additional storage costs and potentially the cost of services that automate and manage backup and recovery processes.
- Data Management and Services Costs: Utilizing cloud services for managing, monitoring, and securing the data lake adds additional costs. This includes services for data cataloging, search, metadata management, and security features like masking, tokenization, encryption, access control, and auditing. The cost depends (once again) on the scale of the data lake and the complexity of the services implemented.
To manage and optimize these costs, organizations typically employ cloud cost optimization approaches that begin with gaining visibility into data lake storage as well as compute services. From there, organizations begin selecting the appropriate storage and compute options, managing data tiering and archival policies, and utilizing reserved instances or savings plans for compute resources. But for data lake storage specifically, do optimizations such as tiering and archival make much difference?
Tiering and archival aren’t widely adopted
Let’s look closer at cloud object storage as it serves as the foundation of modern cloud data lakes, and it is where the bulk of the data volume, growth, and cost lives. In the case of Amazon S3 the vast majority of object storage costs are in "Standard", i.e. the default, highest availability class, and only a tiny fraction are in archival tiers. Given the similarity in data lake capabilities across the major public cloud providers we would also expect the same to be true for Google and Microsoft Azure.
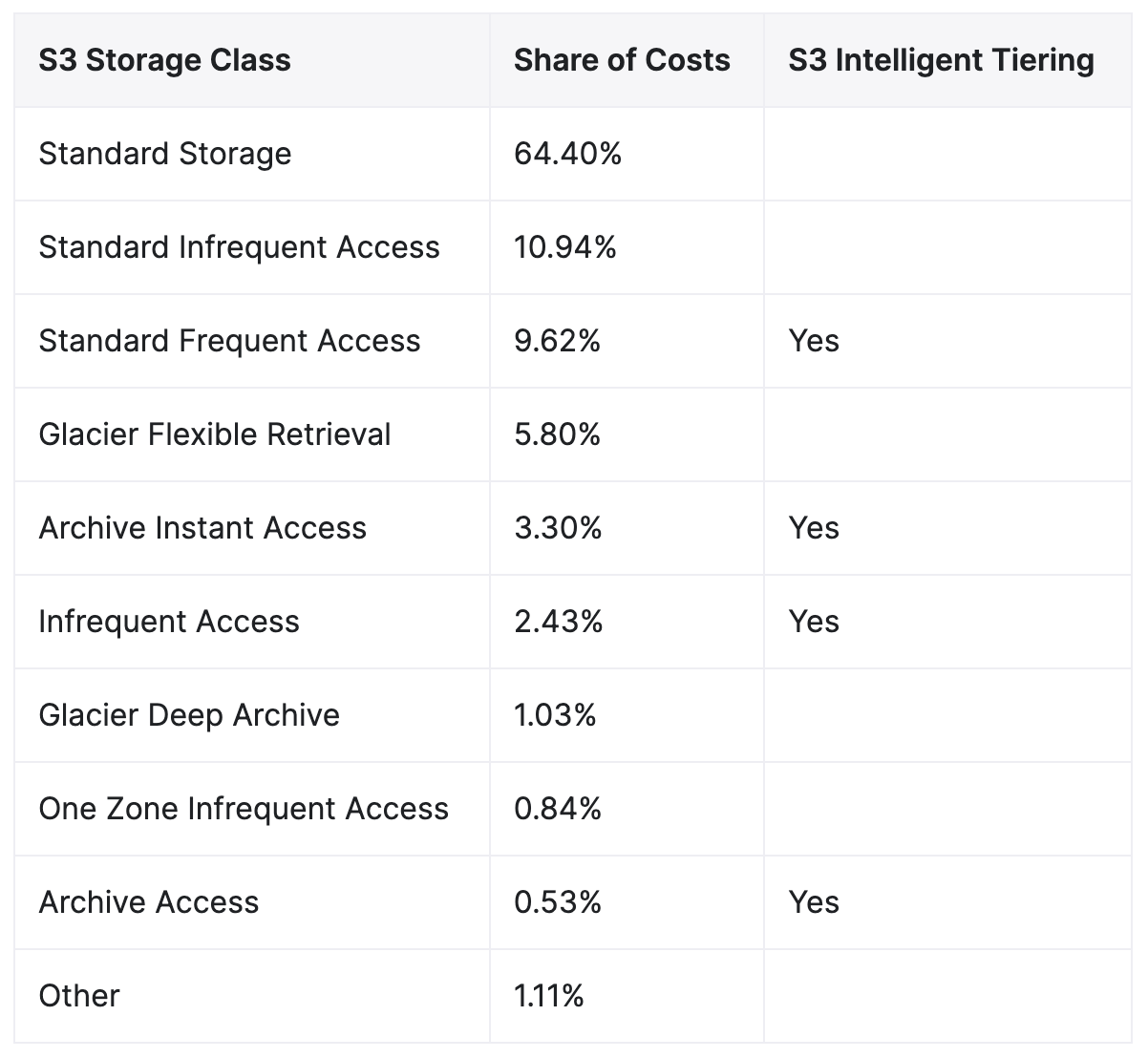
Given the relative per GB price difference, this implies that cloud architects are choosing to keep a large majority of their actual data where it remains fast, has the highest availability SLA, is highly accessible, and remains free of data transfer charges. After all, the point of a data lake is to access and analyze the data, and it isn’t surprising that tiering and archival strategies tend to not be effective.
Data Lake compression to the rescue?
As we saw earlier many cloud data lake costs scale with the number of physical bits - the “at-rest” size of the data. Compression is a familiar technique to reduce the number of these physical bits for a given file or object. If used properly it has great potential to reduce many of the costs discussed above. It directly reduces the cost of at-rest storage including copies made for disaster recovery or analytical use in other regions. And it directly reduces the cost of data and network transfer both within and across regions.
Compression can also indirectly lower the cost of compute where the bottleneck is the speed of reading data from disk, since completing work faster means turning off cloud compute sooner, saving money. Faster analytical processing also means faster insights and better business outcomes - with value potentially much greater than the savings itself.
But compression can also come with some challenges. TLDR: it’s typically really hard to implement and manage at scale. What if it were easy?
Stay tuned for an upcoming blog where we’ll dive into the potential benefits of applying compression, the formidable challenges given current approaches, and (you guessed it) how Granica is addressing those challenges to make petabyte-scale data lake compression an effective solution.
Sign up for a free demo of Granica’s cutting-edge, AI-powered cloud cost optimization solutions to take the next step in your data lake cost optimization journey.
Thoughts? Leave a comment below: