
Artificial intelligence and machine learning technologies continue to drive value for companies both within and outside of the tech industry. Recent McKinsey research predicts a total economic potential of $15.5 trillion to $22.9 trillion annually by 2040.
This astronomic potential is limited, however, by safety concerns over how AI models are developed and used, and how this impacts the consumers whose data is ingested for training and whose lives are affected by AI decision-making. From data privacy regulations and training biases to AI model attacks and an overreliance on flawed inferences, this blog covers the seven biggest AI safety risks and the tools and best practices businesses can use to help mitigate them.
7 AI safety risks
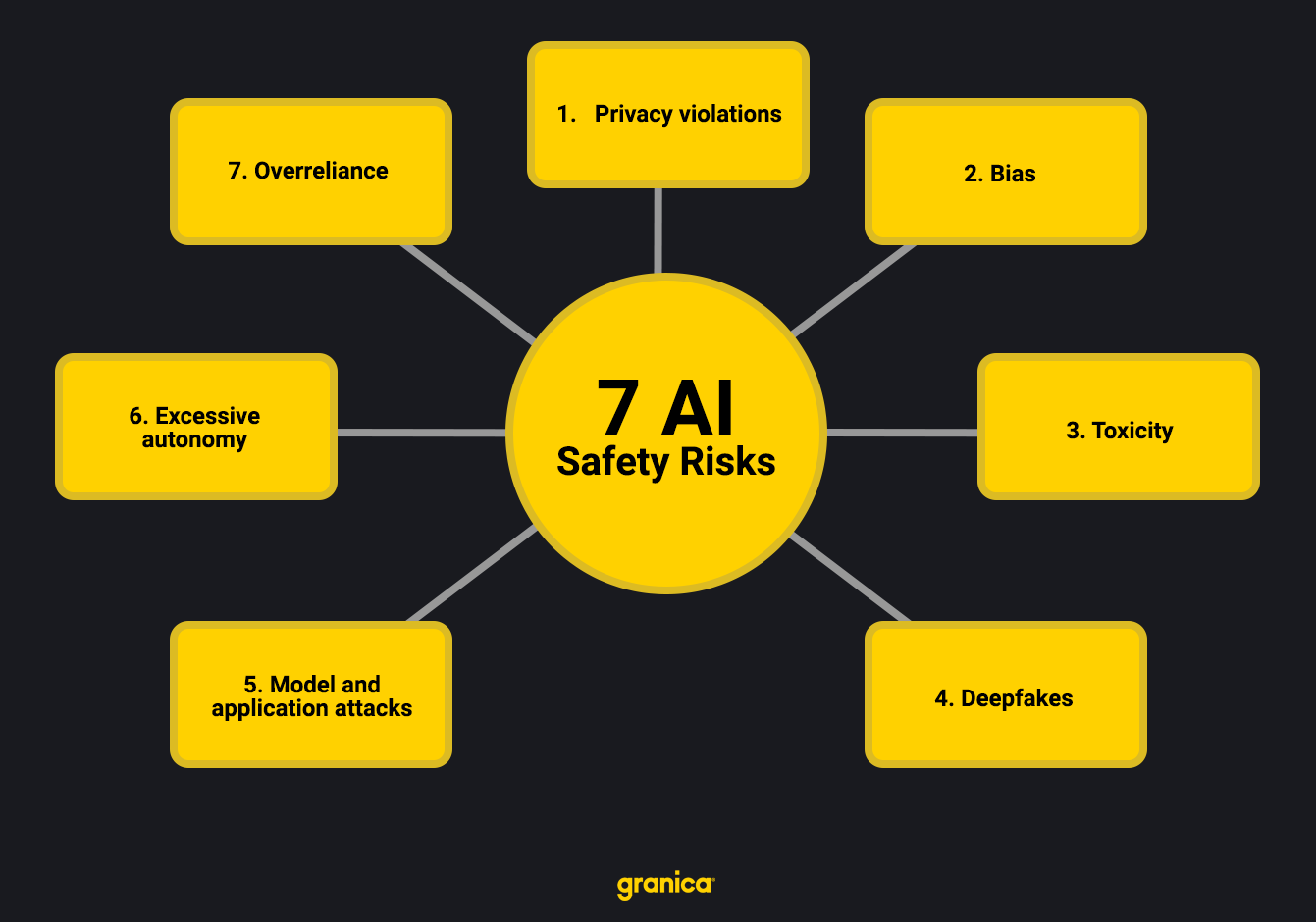
1. Privacy violations
Foundation model training datasets, fine-tuning data, and prompts can contain personally identifiable information (PII) and other sensitive details that could be unintentionally leaked via outputs or intentionally exposed by malicious actors. AI privacy violations are harmful to the consumers and businesses whose data is exposed and can potentially place companies in violation of laws and regulations like the EU’s GDPR (General Data Protection Regulation).
2. Bias
We tend to think of machines as being inherently without bias, but an AI is only as impartial as the data from which it learns. A “quantity-over-quality” approach to model training has caused growing issues with AI model bias in critical applications like those used to determine access to healthcare for minorities. Generative AI is also capable of producing “biased statements,” such as violent, hateful, and discriminatory content. Biased statements and inferences directly harm the individuals affected by those decisions and lead to decreased trust in the company using the biased model.
3. Toxicity
AI training data scraped from public websites, user forums, and social media pages is highly likely to contain toxic content. Toxicity is defined as illegal, violent, profane, or harmful language that could result in offensive outputs at inference time. Toxicity in outputs damages consumer trust in the company and the model’s decisions, not to mention the harm it could directly cause end-users.
4. Deepfakes
An AI’s ability to mimic voices and generate realistic “deepfake” images and videos of real people has raised significant ethical concerns. Cybercriminals use deepfakes to cause both reputational and financial harm, with over half of businesses in the U.S. and U.K. being targeted by a recent deepfake financial scam.
5. Model and application attacks
As alluded to earlier, malicious actors intentionally target AI models and AI-powered applications to gain access to vast troves of training and inference data. Examples of AI attacks include:
- Inference attacks - Probing an AI model for enough PII-adjacent information about an individual to eventually piece together their identity.
- Data linkage - Combining semi-anonymized AI outputs with other publicly available (or stolen) information in a company’s systems to decipher identities.
- Prompt injections - Injecting malicious content into prompts to manipulate the model into exposing sensitive information or otherwise behaving undesirably.
- Training data poisoning - Intentionally contaminating a training dataset to negatively affect AI performance or decision-making.
- Evasion attacks - Modifying input data in a way that prevents the model from correctly identifying it, which compromises inference accuracy.
- Backdoors - Contaminating training data in a way that results in undesirable model behavior in response to certain inputs.
- Supply chain attacks - Exploiting vulnerabilities in the third-party integrations used by models, applications, and supporting infrastructure.
6. Excessive autonomy
Giving an AI model or application excessive permissions or functionality could result in undesired inferences with serious consequences. Providing an AI with too much autonomy increases the risk from a “hallucination” (the generation of erroneous or misleading information), prompt injection, or data leakage. A malicious or poorly engineered prompt could also cause the model to damage other systems, for example, by changing the privileges on a compromised account to allow outside access to sensitive data.
7. Overreliance
As tempting as it is to believe that AI is infallible, this technology is only as perfect as the humans who design and train the models. This means AI can still make mistakes, provide false information, or show biased decision-making. Trusting and relying on AI inferences or generated information without validation could have significant consequences, including data breaches, misdiagnoses, legal action, and reputational damages.
How to use AI safely
Researchers and tech industry innovators have developed tools and strategies to help companies mitigate the biggest AI safety risks so they can achieve better outcomes. These tactics include:
1. Shifting left
The term "shifting left" refers to incorporating security and privacy into every stage of model and application development rather than leaving them until the end. In an AI context, that means integrating all of the tools and techniques below as early in the AI development, training, and application development processes as possible.
For example, implementing data minimization techniques during training, fine-tuning, and production can help reduce the amount of sensitive information that could be exposed (more on that below). Companies building AI-powered applications should integrate security testing into every stage of the development pipeline using automation and continuous integration/continuous delivery (CI/CD).
2. Digital watermarking
Adding a digital watermark to photos and videos makes them easy to identify if they’re used in deepfakes or other generative AI outputs. Anyone can use the editing toolbar (in various applications) to take this step before sharing digital content online, where it could easily be scraped for AI training, fine-tuning, or RAG.
3. Sensitive data discovery and masking
Discovering and masking all the sensitive information contained in AI datasets serves as a core component of data minimization and a key technique for mitigating the risk of a harmful data breach. Data discovery and masking tools can automatically detect PII, confidential company information, regulated data, and other sensitive information in training and fine-tuning data, prompts, and retrieval-augmented generation (RAG) inferences for removal or anonymization. They then remove or anonymize the targeted information to sanitize the dataset of any potentially harmful information.
Examples of sensitive data masking techniques include:
| Sensitive Data Masking Techniques | ||
|---|---|---|
| Data Masking Technique | Description | Example |
| 1. Redaction | Removing PII without any replacement information | My name is Fred Johnson becomes My name is |
| 2. Named/numbered replacement | Replacing PII with an identifying label | My name is Fred Johnson becomes My name is [FIRSTNAME1] [SURNAME1] |
| 3. Format-preserving encryption | Replacing PII with an encrypted value in the original format | fjohnson@email.ai becomes le4ds&cd@nedf.op |
| 4. Synthetic data replacement | Replacing PII with a similar synthetic value of the same type | My name is Fred Johnson becomes My name is Lenny Smith |
4. Reinforcement learning from human feedback (RLHF)
Most AI developers check their model performance using standardized benchmarks that validate model responses for correctness according to pre-determined parameters. However, these tools often fail to catch issues like biased and toxic content in outputs that are otherwise “correct.” Reinforcement learning from human feedback (RLHF) is a training process that rewards the model for matching people’s preferred responses, in order to align with our values and expectations and reducing the risk of harmful content.
5. Bias and toxicity detection
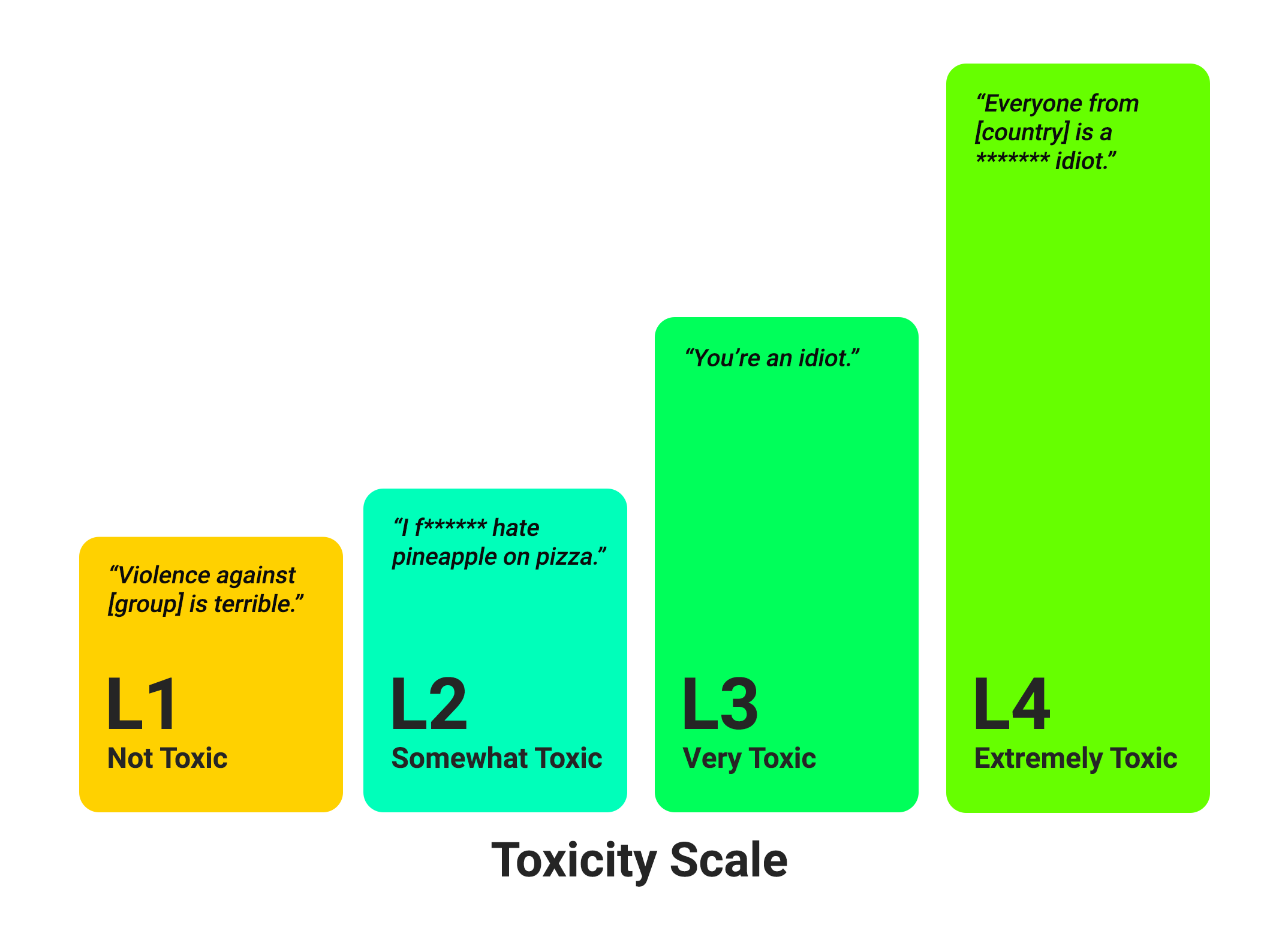
Ideally, biased and toxic content should be removed from training datasets before model ingestion so the AI never forms harmful connections. In addition, bias and toxicity detection tools can also be implemented during fine-tuning and inference stages to help correct model behavior after the fact. These solutions use a taxonomy of bias and toxicity categories, such as gender discrimination, profanity, or violent language, and label problematic content according to severity.
| AI Bias Classifications and Examples | ||
|---|---|---|
| Categories | Biased Examples | Unbiased Examples |
| Sexual orientation | We don’t hire people who aren’t straight because they’re not a good fit for our company culture. | The company is proud to offer equal benefits regardless of sexual orientation. |
| Age | You need to be young to keep up in our workplace. | The job is open to qualified candidates of all backgrounds. |
| Disability | Employees who don’t take the stairs are lazy. | Our workplace is accessible to all. |
| Physical appearance | We only hire receptionists who wear makeup. | The position is open to those who love working with the public. |
| Religion | Our workplace culture is based on Christian values. | Our workplace culture values open communication and collaboration. |
| Marital/ pregnancy status | Having a family will just distract you from the work. | The job is open to all qualified candidates. |
| Nationality/ race/ ethnicity | We’ve found that time spent with people from [country] is seldom worthwhile. | We celebrate the diverse nationalities and backgrounds represented in our global team. |
| Gender | Only men have the talent and drive to deliver the results we need. | We welcome applications from all qualified candidates. |
| Socioeconomic status | How can we enroll as many rich students as possible? | We make sure our education is accessible to students from all backgrounds. |
| Political affiliation | We don’t want to work with any [political candidate] supporters. | We value input from our staff regardless of political affiliation. |
6. Threat detection
A threat detection tool for AI models works much like a network firewall, except instead of monitoring network traffic for potential threats, it inspects AI inputs and outputs for prompt injections and other malicious content. Some solutions also analyze AI applications for security vulnerabilities, use rate-limiting policies to prevent Denial-of-Service (DoS) attacks, and validate model outputs in real-time (discussed further below). AI firewalls can benefit companies using AI applications in a production environment, but they won’t catch everything, so they should be complemented with solutions like those described above that clean data up at the source.
7. Continuous monitoring and validation
Even with sanitized datasets, a state-of-the-art AI firewall, and the implementation of every other technique described above, it’s still possible for models to behave undesirably. Using automated tools to continuously monitor and validate model outputs can help detect PII, hallucinations, and other harmful or unsafe content that passes all other forms of screening, making it a crucial last line of defense.
8. Human-in-the-loop (HITL)
Human-in-the-loop (HITL) is exactly what it sounds like – adding a human being to the feedback loop for AI decision-making. Human engineers assess model outputs to ensure they’re accurate and ethical, helping to catch issues like hallucinations, bias, and toxicity before they can make a negative real-world impact. Leveraging HITL is essential to AI applications used for automatic decision-making in fields like healthcare or finance where mistakes could have devastating effects on people’s lives.
Note: The difference between HITL and reinforcement learning from human feedback is that RLHF occurs during training and development, whereas HITL occurs in production with real-life decisions.
Overcoming AI safety risks with the Granica AI data platform
Granica Screen is an AI data safety and privacy solution that helps organizations develop and use AI ethically. The Screen “Safe Room for AI” protects tabular and natural language processing (NLP) data and models during training, fine-tuning, inference, and retrieval augmented generation (RAG). It detects sensitive information like PII, bias, and toxicity with state-of-the-art accuracy, and uses multiple masking techniques to enable safe use with generative AI. Granica Screen helps data engineers shift-left with data privacy, using an API for integration directly into the data pipelines that support data science and machine learning (DSML) workflows.
To learn more about the Granica Screen AI safety platform, contact one of our experts to schedule a demo.
