

Modern AI is hungry for data and thus procuring high quality, large labeled datasets for training models has taken center-stage. However, training on increasingly large datasets comes with significant hurdles. In supervised machine learning tasks, labeling datasets is notoriously laborious, time consuming and expensive. Larger datasets also increase training compute costs and time, as well as storage costs.
However, not all training data points (or samples) contribute equally to the model performance and accuracy as they might be redundant or of low-value. For instance, take the scenario of object detection from images collected by an Autonomous Vehicle (AV). Not all images would contribute equally to the task of (say) pedestrian detection as most of them would just contain roads and neighboring cars. In fact, recent empirical studies [1, 2, 3, etc.] show that we can often throw away a significant fraction of the training data without losing any performance.
This is intriguing, but it raises a host of questions. When is it possible to subsample a large dataset and still retain model performance when training on the smaller set? What are optimal schemes to select the most valuable data? In our recent research paper Germain Kolossov, Pulkit Tandon and I studied the problem of optimal data selection both theoretically and empirically leading to multiple surprising findings. The paper will be presented orally at ICLR 2024.
In this blog we’ll go through our findings at a reasonably high level. For the math-inclined we will have a more technical follow-up blog post.
Problem formulation
In our work, we study data selection under weak supervision. We assume we don’t have access to the labels for our training data, but we do have access to surrogate models which are trained on far fewer samples than the original unlabeled dataset, or on different data sources. We use these weakly supervised models to generate “importance” scores for each sample in the original unlabeled dataset based solely on data features.
Subsequently, we use these scores to filter the samples into smaller data subsets. Finally, we acquire labels for these subsets and use the feature-label pair for training. We used this setup to study data selection properties for training of classification models across both synthetic and real data. Here’s what the process looks like:
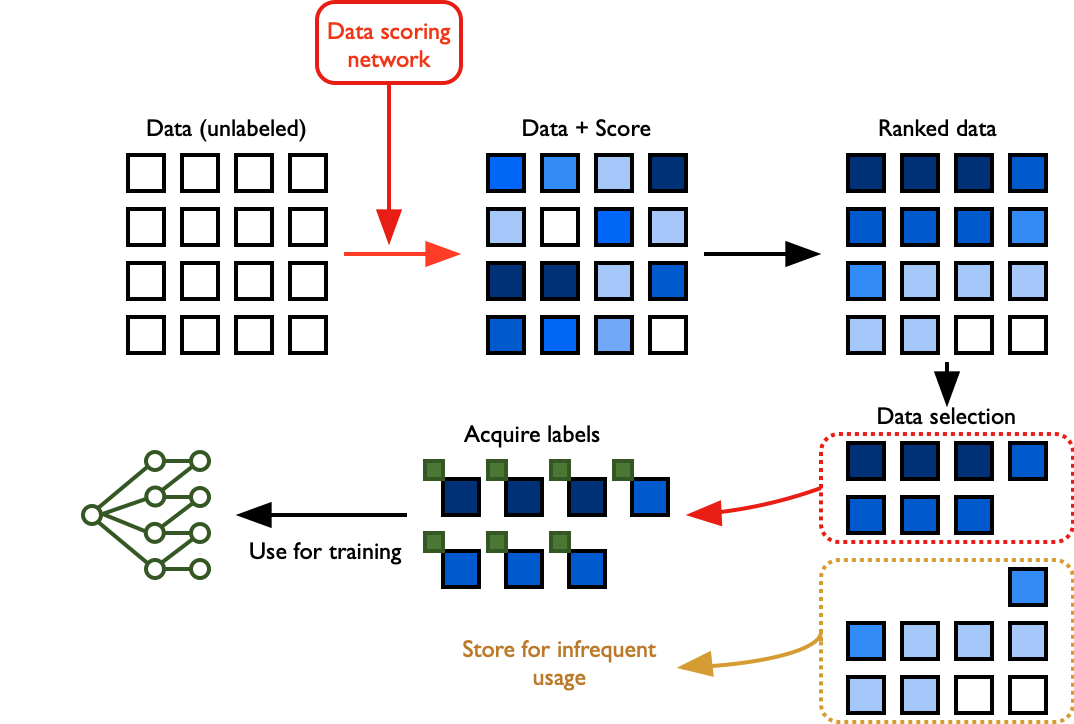
Experiments and results
We studied a number of data selection schemes both theoretically and via experiments. Our theoretical analysis applies to relatively simple data models, and, in these settings, is able to perfectly predict the misclassification error under various subselection schemes. Despite the relative simplicity of these data distributions, these results display a variety of interesting behaviors and insights. It would have been extremely difficult to anticipate such behaviors on the basis of simple intuition.
This variety is reflected in our experiments which investigate the performance of our data selection scheme on a real autonomous vehicle dataset. We created a binary image classification task of classifying cars in images from the KITTI-360 dataset. We again train our models after data selection on feature vectors obtained from SwAV embeddings on these images.
Let’s explore the results.
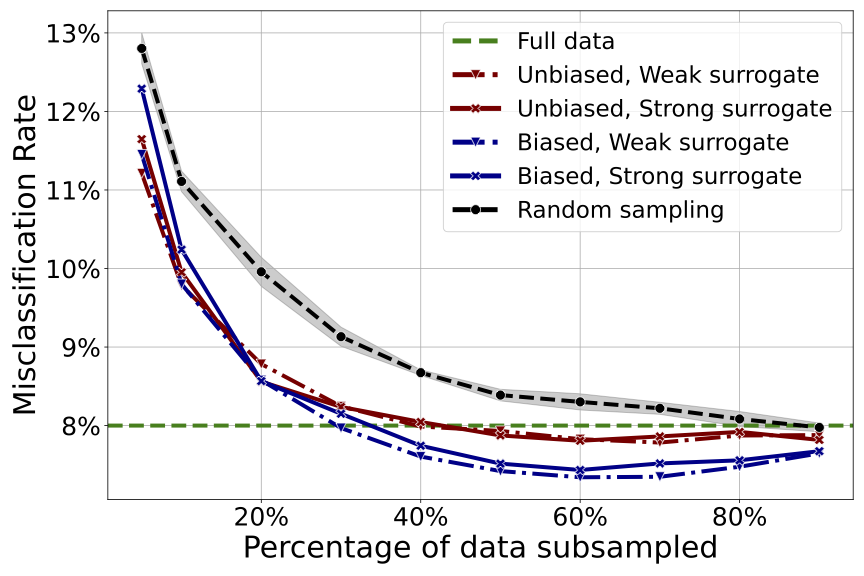
The first chart plots the error probability of the model (the “Misclassification Rate”) against the size of the subset used for training the image classification model. The bigger the “Percentage of data subsampled”, the larger the subset. In this plot “better” is “down and to the left”. In other words, what we’re looking for is the lowest Misclassification Rate (highest accuracy) at the smallest “Percentage of data subsampled” (smallest dataset size).
At a high level we see that (not surprisingly) the model generally gets more accurate with more data, and it’s also obvious that there are diminishing returns. But more interestingly, not all curves are monotonically decreasing. In some cases, a model trained on 40% of the original data has a lower error rate than one trained on the full dataset! By labeling and training on the (significantly smaller) sampled dataset, we can benefit from a corresponding reduction in cost and time.
Surprise 1: Biased subsampling can improve model accuracy
We see that by keeping a mere ~30% of the data (a 70% reduction) we can match the accuracy of the model trained on the entire dataset. Even more surprisingly, by keeping only ~60% of the data (a 40% reduction) we can actually improve the model accuracy! This is counter-intuitive as it seems to suggest that throwing away data can improve model performance.
A naive (and somewhat less interesting) explanation could be that the model trained on 50% subsampled data is effectively leveraging the samples used to train the surrogate model. In other words, we are not correctly counting the total number of samples used. However, the surrogate can be trained on a very small percentage of the data (4% for the ‘weak’ surrogate) and yet retain its power. So what’s happening and how do we explain it?
As mentioned above, we develop theoretical models in which the same phenomenon can be proved mathematically. This reassures us that what we observe empirically is not an exception, but a widespread phenomenon. The reason this is counterintuitive is that we normally assume that training optimally exploits the information contained in each data sample. If this was the case, removing data could not possibly help.
The reality is that machine learning models and loss functions can be mismatched to the actual data distribution. When this happens, not all data samples provide new information, and some data samples can actually introduce more noise in the estimates than actual information. The data scoring scheme filters out those data, hence improving the training.
Surprise 2: Use of weaker surrogate models can outperform stronger surrogate models
We expected that leveraging a stronger surrogate model (higher accuracy) would always lead to a better data selection scheme compared to leveraging a weaker surrogate model because it would have seen more data. Surprisingly, we found this wasn’t the case, and that selection schemes leveraging weak and strong surrogate models perform similarly. Moreover, we even found cases where weaker surrogate models perform better than stronger ones.
This finding can be quite helpful in practice, as it suggests that we don't need ever-larger surrogate models trained on enormous amounts of data to obtain a sampling scheme that can perform on par with full sample estimation.
Insight: Uncertainty-based subsampling is effective
The simplest rule of thumb emerging from our work broadly confirms earlier research: subsampling schemes based on the sample ‘hardness’, i.e. on how uncertain surrogate predictions are, perform well in a broad array of settings.
Indeed, this is in line with recent research on data attribution that uses scores based on so-called ‘influence functions’. The latter measures the impact of a single datapoint on the training. However, even here there are surprises. While it is standard wisdom that samples with the largest influence are the most important (these are also the ‘hardest’ to predict), we observe that sometimes it is instead the samples with lower influence (the ‘easiest’) that are important to keep in the sample.
Generally speaking, in low-dimensional cases, stronger bias towards ‘harder’ examples is beneficial while in certain high-dimensional cases bias should be towards ‘easier’ examples. Having said that, selecting the ‘hardest’ or ‘easiest’ even in high dimensional cases is not always optimal. For instance, in some cases biasing towards ‘harder’ samples can be beneficial in high-dimension, but selecting the ‘hardest’ ones, e.g. those that have the largest value of influence, can lead to significant failures.
The implication here is that realizing the full potential of data subselection, while avoiding any downsides, is not trivial and rather requires a high degree of sophistication and insight. Of course, this is precisely the type of difficult problem that we at Granica thrive on solving.
Summary
Choosing the right data for machine learning models isn't just beneficial; it's imperative for the efficiency of today's data-intensive models. Opting for high-quality data elevates model performance while simultaneously slashing the substantial costs tied to infrastructure, computation, and storage needed to manage vast datasets. Furthermore, the automation of this selection process transforms data management practices, freeing up extensive resources that companies typically devote to labeling, curating, and maintaining data quality pipelines for machine learning models.
At Granica, we uphold the principle that superior, trusted AI is built on the foundation of exceptional training data management. We’re excited to share our latest research into data subselection and we look forward to providing updates as we explore the possibilities it opens up.
Sign up for a free demo of Granica’s cutting-edge, AI-powered data privacy and cost optimization solutions to take the next step in your trusted AI journey.
Thoughts? Leave a comment below:




