Computer vision datasets are rapidly growing, demanding substantial storage space. For instance, the Laion 5 billion dataset requires over 200 TB of disk space. Storing such massive datasets can be both challenging and costly. However, there are effective strategies to manage storage without sacrificing the quality of training images for machine learning models.
When working with a fixed storage budget, we have two primary options: maintaining fewer high-quality images or using lossy compression to store more images at a reduced quality. Modern image codecs provide a range of compression settings, allowing us to choose the optimal balance between image quantity and quality.
The default approach often leaves images uncompressed, but research shows that lossy compression can offer a superior trade-off. Models trained on compressed images can achieve lower test errors compared to those trained on fewer, high-quality images. By experimenting with various compression levels and image quantities, we observe that test error follows a predictable power law in relation to the number of images and their compressed sizes.
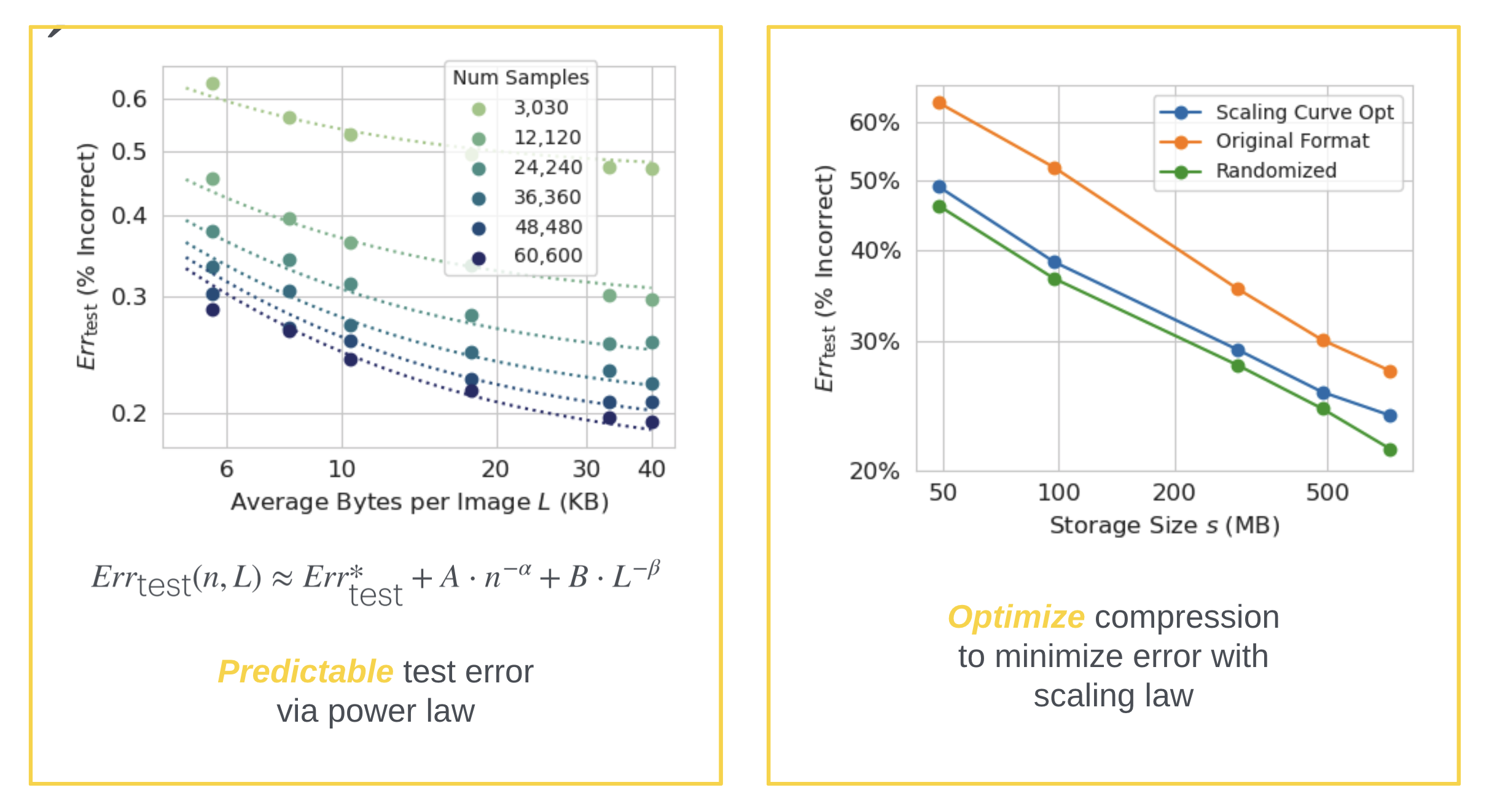
These scaling laws enable us to optimize image compression levels to minimize test error within a given storage budget. Compared to simply discarding images to fit storage constraints, training on optimally compressed images results in lower test errors for the same storage capacity.
In practice, this means that when faced with storage limitations, lossy image compression is a viable alternative to reducing dataset size by deleting images. For a more in-depth understanding, check out our paper on scaling training data with lossy image compression.
You can also check out our Research page for other papers in data-centric AI.