Explore your data environment with genAI-powered prompts that generate relevant visualizations in graphs and tables to uncover actionable insights, fast.
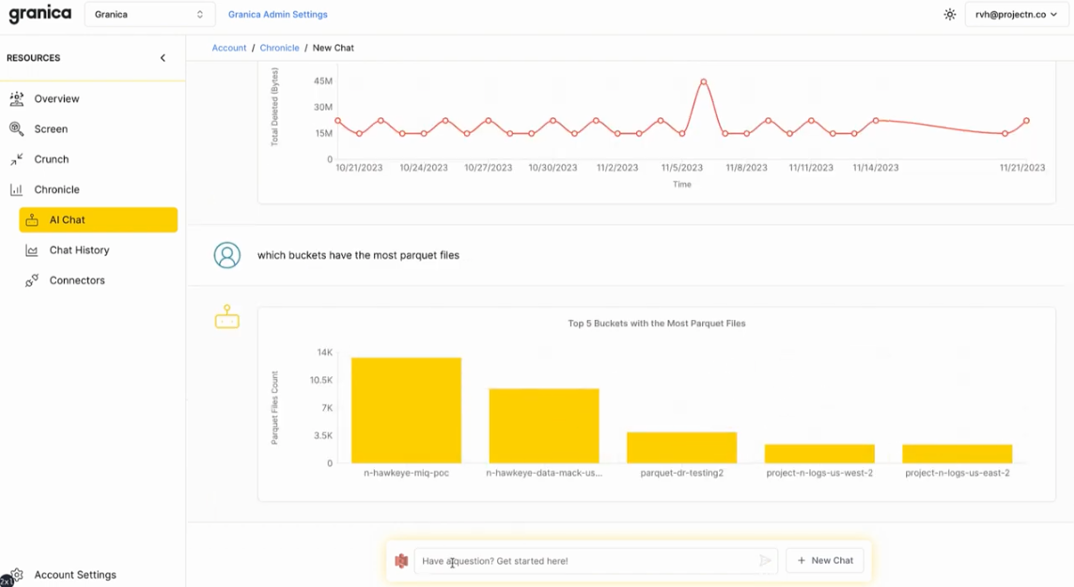
Use natural language to ask questions of your data lake buckets and files and get answers.
Discover valuable training data, understand usage and access patterns for AI applications, and more.
Get relevant visualizations in graphs and tables - no SQL, CLI, or dashboard creation required.
Data types supported
Granica Chronicle AI supports any and all file types in your data lake.

Text/NLP

Clickstream/Logs

Tabular
LiDAR/Image
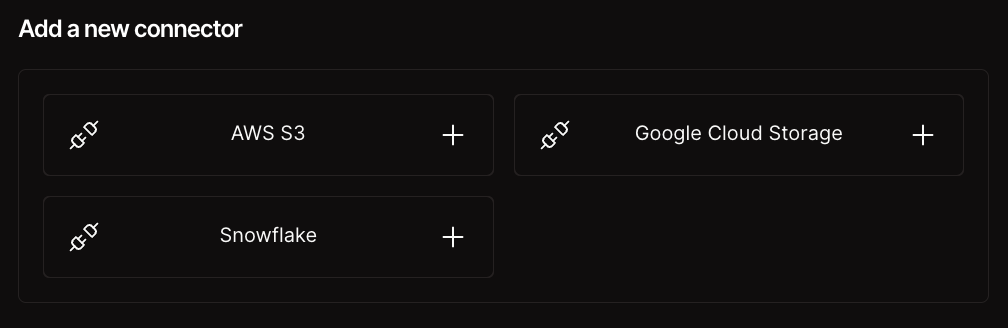
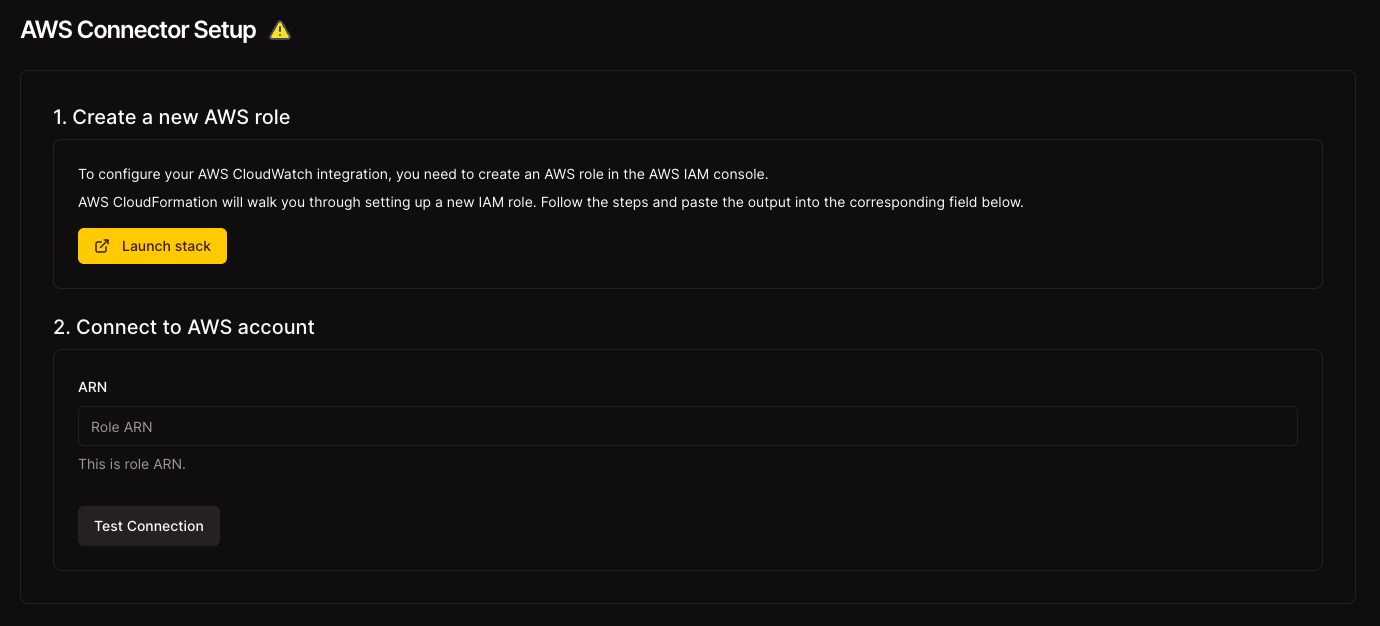
 Get the latest Gartner® research: A Journey Guide to Delivering AI Success Through AI-Ready Data
Get the latest Gartner® research: A Journey Guide to Delivering AI Success Through AI-Ready Data