It’s hard to control cloud costs for ever-growing data while experimenting with AI. Even with low-cost cloud object storage backing your data lakehouse, a single PB of Parquet data has an annual at-rest cost of nearly $300k/year.
Tiering into colder, less expensive cloud storage classes doesn't work for analytical and training data given it is regularly accessed. Manually optimizing the compression and encoding of Parquet to lower cloud costs is complex and risky.
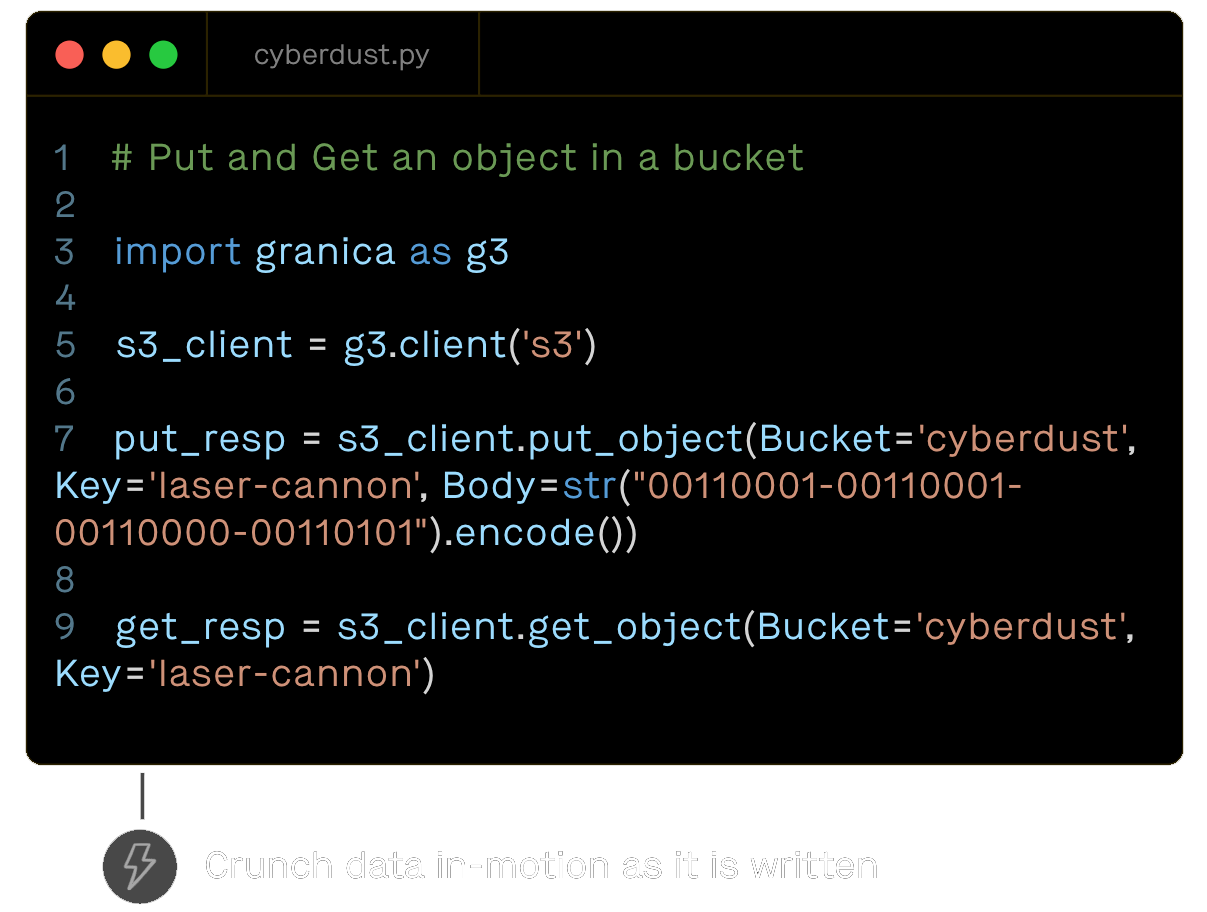
What data teams need is a way to automatically optimize compression of Parquet to lower cloud costs and speed access, analogous to how query optimizers increase query performance. We created Granica Crunch to solve this problem.

60%
Crunch shrinks the physical size of the columnar files in your cloud data lakehouse, lowering at-rest storage and data transfer costs by up to 60% for large-scale analytical, AI and ML data sets.

60%
Smaller files also make cloud data transfers and replication up to 60% faster, addressing AI-related compute scarcity, compliance, disaster recovery and other use cases demanding bulk data transfers.

56%
Smaller files are also faster files - they accelerate any data pipeline, query or process bottlenecked by network or IO bandwidth. Up to 56% faster based on TPC-DS benchmarks.

Slash the cloud storage costs for your Parquet data lakehouse files. Use our simple 2-input calculator to get a preliminary estimate.
whitepaper
Read Our Latest White Paper "Building Trust, Impact and Efficiency into Traditional and Generative AI

Granica’s cloud cost management platform helps reduce your unit economic cost to store lakehouse data. Capture recurring savings relative to your pre-Granica baseline each and every month, not just once. Ten petabytes of existing columnar data typically translates into an annual gross savings of ~$1.2M, scaling as your data lakehouse grows. Crunch helps you meet your most crucial cloud cost optimization KPIs for both cost and performance.


What’s truly meant by the term AI-ready data, and what are the best approaches to successfully deliver AI-ready data aligned to AI use-cases? Download Gartner's latest research report to learn how AI efforts are evolving the data management requirements for organizations, compliments of Granica.

Top Cloud Cost Management Tools: 2024 Review

Cloud Cost Optimization: The Ultimate Guide

Google Cloud Cost Optimization Guide
g ~/ granica deploy
Success!
g ~/
 Get the latest Gartner® research: A Journey Guide to Delivering AI Success Through AI-Ready Data
Get the latest Gartner® research: A Journey Guide to Delivering AI Success Through AI-Ready Data 
