
As artificial intelligence and, in particular, generative AI (genAI) adoption continues to rise, so do concerns about model security and accuracy. According to recent McKinsey research, 51% of organizations viewed cybersecurity as a major AI-related concern and 63% recognized model inaccuracy as a relevant risk.
On the other hand, the same report found that organizations are finally starting to see value from their AI investments, particularly in business functions like supply chain and inventory management. Addressing AI security concerns with a thoughtful, multi-layered strategy can help mitigate risk while improving model accuracy, allowing companies to maximize value.
This blog outlines five of the biggest AI security challenges to overcome before describing the tools, techniques, and best practices for improving AI outcomes.
AI security concerns
Some of the biggest AI security concerns and challenges include:
 Software and hardware exploits
Software and hardware exploits
AI models, software integrations, and supporting infrastructure could contain vulnerabilities that malicious actors can exploit to access sensitive data or interfere with model performance.
 Training data interference
Training data interference
Malicious actors may tamper with the data used to pre-train or fine-tune an AI model, negatively affecting inference accuracy or causing otherwise undesired behavior.
 PII in training and inference data
PII in training and inference data
The data used for model fine-tuning, prompt engineering, and retrieval augmented generation (RAG) may contain personally identifiable information (PII), increasing the risks of compliance issues, accidental leaks, and targeted data breaches.
 Regulatory compliance
Regulatory compliance
Since AI models ingest data and prompts from all over the world, model developers and operators must maintain compliance with a wide variety of region-specific data privacy regulations. This regulatory landscape is constantly evolving to deal with AI privacy issues like deepfakes, which further increase compliance complexity.
Click here for a list of current AI-related data privacy regulations around the world.
 Targeted AI attacks
Targeted AI attacks
Cybercriminals use increasingly sophisticated threats to target AI models because they want to manipulate model behavior for sabotage or fraud, seek sensitive information, or simply wish to exploit AI models' “inexplicability” to avoid detection.
Examples of targeted AI attacks
| AI Attack Type | Description |
|---|---|
| Poisoning | Intentionally contaminating a training dataset to negatively affect AI performance or behavior. |
| Inference | Probing an AI model for enough PII-adjacent information to infer identifiable data about an individual. |
| Data linkage | Combining semi-anonymized data outputs from an AI model with other publicly available (or stolen) information to re-identify an individual. |
| Prompt injection | Inserting malicious content into AI prompts to manipulate model behavior or extract sensitive information. |
| Evasion | Modifying input data in a way that prevents the model from correctly identifying it, compromising inference accuracy. |
| Backdoors | Contaminating a training dataset in a way that results in undesirable model behavior in response to certain triggers. |
| Training data extraction | Probing a target AI model to reveal enough information for an attacker to infer some of the training data. |
| Infrastructure attacks | Targeting the underlying hardware and software that supports the AI model to gain access to sensitive data or compromise model performance. |
A safe path forward for AI
Taking a multi-layered approach to model security can help companies address AI security concerns while improving model performance, accuracy, and overall outcomes.
Layer 1: Attack mitigation
Organizations should implement targeted security policies, procedures, and tools that defend against AI-specific attacks like those described above. Examples of AI attack mitigation tools and techniques include:
-
Using AI firewalls like Nightfall AI to validate training data, inputs, and outputs and help protect against poisoning attempts, prompt injection, and training data extraction.
-
Bias and toxicity detection tools like Granica Screen monitor model inputs and outputs to prevent unwanted behavior and improve model objectivity. Toxicity refers to offensive or otherwise undesirable language that could be the result of poisoning or prompt injections.
-
Sensitive data screening tools like Granica Screen discover and mask PII in training data and inputs, protecting against inference, data linkage, and training data extraction. Granica Screen also generates realistic synthetic data to mask PII, protecting privacy while providing more context for inference, which improves model accuracy.
-
Ensemble learning and Private Aggregation of Teacher Ensembles (PATE) are two related techniques that involve distributing training datasets and using multiple sub-models rather than one large model. Breaking up data and inference capabilities helps prevent poisoning and training data extraction.
-
Automatic patch management applies security updates as soon as they’re available to defend known vulnerabilities in software, hardware, and third-party dependencies in AI model infrastructure.
Layer 2: Model security
While it’s important to defend against known threats, malicious actors are using adversarial AI models to create sophisticated new attack vectors at a pace that cybersecurity tools and analysts can’t possibly keep up with. This makes it imperative for technology leaders to select a third-party AI solution developed according to secure practices – or take a security-first approach to developing their own models.
For example, a major reason that AI-targeted attacks are difficult to detect is that most models are still “black box” systems with poorly understood decision-making logic and inference bases, making it impossible to anticipate and protect model vulnerabilities. Developing artificial intelligence according to the Explainable AI (XAI) methodology allows human engineers and operators to understand how the model works, which makes it possible to analyze and defend weaknesses.
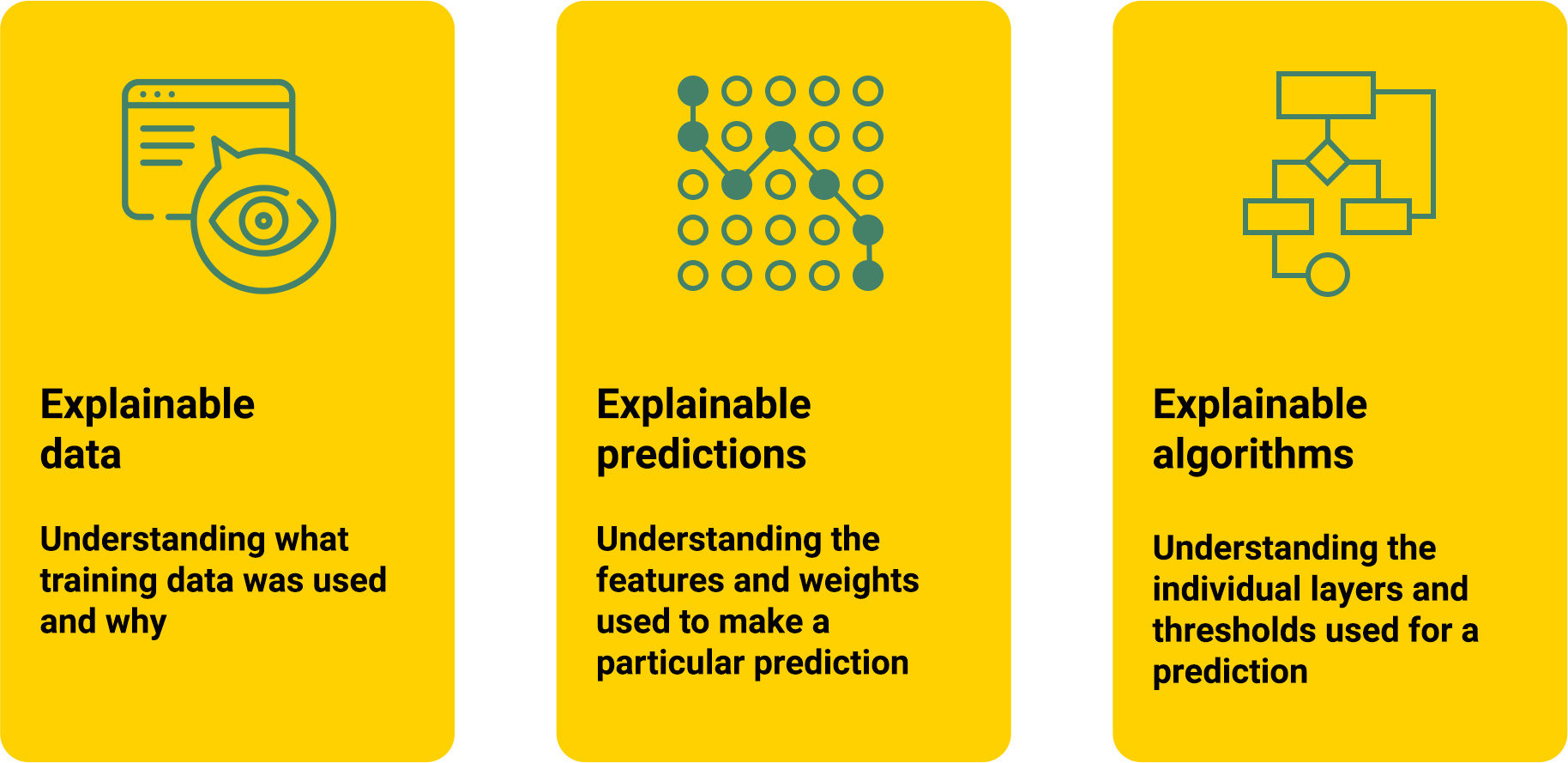
Another important model security concept is continuous validation of model security and performance. Testing continuously throughout the development and training processes can help detect any vulnerabilities that arise as the model’s inferences grow more complex and its capabilities are extended through APIs and other third-party dependencies.
Layer 3: Infrastructure security
An AI model or application isn’t truly secure unless its underlying systems are adequately protected. AI infrastructure security best practices include:
-
Isolating a model’s control mechanisms from the functional modules to reduce the attack surface for inference and data linkage attacks.
-
Isolating the control plane for servers, networking devices, and other equipment to prevent malicious actors from using stolen credentials to jump from a compromised endpoint to an AI system’s critical control mechanisms.
-
Using policy-based access control (PBAC) with context awareness to prevent unauthorized access to AI systems and data in a way that’s scalable to the large number of authorization rules required for LLMs and other AI technologies.
-
Automating patch management to ensure infrastructure vulnerabilities are patched as soon as possible, and integrating CVE (common vulnerabilities and exposures) tools to limit exposure.
-
Deploying redundancies like multi-model AI architectures, real-time data backups, and geographically distributed load balancers to make AI models and their underlying infrastructures more resilient to attacks and failures.
-
Using infrastructure observability tools like Security Orchestration, Automation, and Response (SOAR) and AIOps to continuously monitor systems for threat indicators and streamline incident response.
For a more in-depth analysis of AI security concerns and protection strategies, download our AI Security Whitepaper.
Opportunities for CIOs, CISOs, and CDAOs
Implementing a strong, multi-layered AI security strategy helps mitigate breach risks and compliance issues, ultimately saving organizations money in the long run. However, a secure AI strategy also allows companies to safely use more data for training and inference, thereby improving AI outcomes.
Cleansing AI data of PII and toxicity allows more data to be used in training, fine-tuning, or RAG inference, providing more context to improve model accuracy. A tool like Granica Screen can help detect PII, toxicity, and bias to improve the efficacy, fairness, and trustworthiness of model decisions.
Screen is a data privacy service for training data, prompts, and outputs in cloud data lakes and lakehouses. It works in real-time with extremely high accuracy, detecting PII, toxicity, and bias in data and masking sensitive information with realistic synthetic data before it’s passed to the genAI model. As part of a multi-layered AI security strategy, Granica Screen can help drive business value for critical AI investments.
Get an interactive demo of Granica Screen to learn how it can help you overcome your biggest AI security concerns.