This post is part of a series of posts on our bias and toxicity detection feature in Granica Screen - see Part 1 here for more background on detecting biased and toxic content and challenges associated with this task.
What can we get out of screening for bias and toxicity?
We wanted to build the best possible tool for organizations wanting to easily scan any text they’re working with for harmful content. In AI and ML-related settings, there are numerous applications where this can be useful, such as:
- Reducing the toxicity in large language models, by filtering out harmful or dangerous training data from datasets
- Scaling up content moderation workflows, by prioritizing high risk content for human review
- Adding guardrails and detailed quality control metrics to chatbots and AI agents
- Adding the toxicity and bias predictions as new, high-quality, synthetic features, enriching existing training datasets
- Enhancing the RLHF training process, by incorporating toxicity scores as an auxiliary reward signal, in order to help better identify preferable model outputs
Challenges and limitations of current approaches
There are several widely-used data safety solutions for detecting harmful content, but we found that there were still important unmet needs for models:
1. Lack of severity granularity
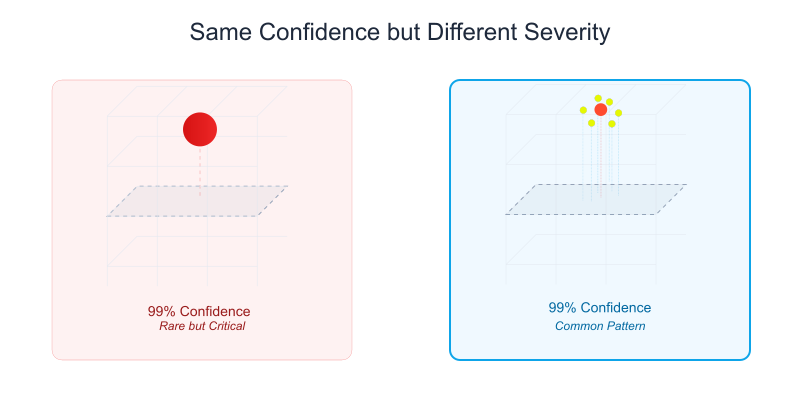
Almost all existing data safety solutions treat the task of bias and toxicity detection as a multiclass binary classification task, collapsing both harm severity and model uncertainty into a single probability score. Rather than merely deciding if a piece of content is toxic, we often need to know how toxic it is. This highlights the need for models that provide more granular outputs specifically addressing the issue of severity.
For instance, consider a content moderation system that assigns both of these texts a p(unsafe) = 99% score:
- Text 1: a chatbot providing direct instructions for self-harm or suicide to a user
- Text 2: a typical internet insult where one user hurls obscenities at another
While both receive the same “unsafe” probability, the reasons differ significantly. One is truly severe and extreme, while the other is a familiar, if offensive, pattern. Without separate severity modeling, we can’t distinguish between the gravity of these two scenarios.
This distinction matters in practice because different types of harmful content need different responses. Ideally, we’d want both:
- human visibility into the most significant examples of harmful inputs or outputs
- operation at huge scale
These two goals can be hard to satisfy simultaneously without triaging limited content moderation resources - hence the need to prioritize examples accurately.
When our systems can’t tell whether they’re confident because they’ve seen lots of mild insults or because they’ve identified severe harm, we end up misallocating our limited resources. We might focus too much on common but less harmful content - and miss the rare but consequential cases that need immediate human attention.
Additionally, you can’t solve this problem just by calibrating your binary prediction model better - continuing with the above example, whenever the model predicts 99% chance of toxicity, 99 out of 100 outcomes for such predictions may very well indeed be toxic - but you would still have fundamental uncertainty about what that tells you about how much qualitatively more offensive that text is when it’s compared to a text that got eg a 75% chance of toxicity.
2. Lack of categorical granularity
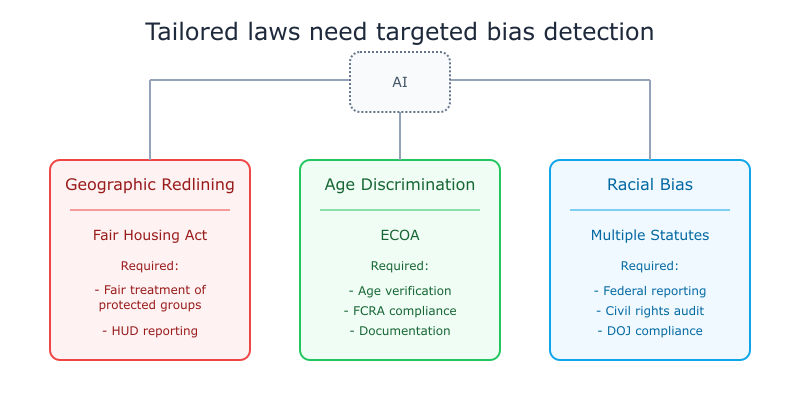
Some examples:
- verifying protections for each specific protected characteristic group
- legal jurisdictions with strict laws against ethnic or religious hate speech, or where documenting hate incidents is legally mandated
- data-driven policy improvements, transparency, and development
In each of these scenarios, there is additional utility for distinguishing between harm types at a more granular level.
At a high level, many safety models have categories that have to do with ‘toxicity’ or to do with ‘bias’. While they typically provide some granularity for the toxicity categories, they often lack granularity for bias categories.
However, most bias and toxicity detection tools do not distinguish sufficiently between different forms of bias, typically using a “Hate speech” or ”Discrimination” catch-all category. The problem with this is that it’s not informative enough to be actionable. Suppose a company discovers they’ve violated anti-discrimination laws – how can they take swift corrective action if they don’t know which group had been affected?
It’s also worth pointing out that, worldwide, most companies and governments are already operating within some given regulatory framework about safeguarding protected groups. So this isn’t a suggestion that the field of machine learning come up with new definitions for categories, but rather just to work within the well-established ones.
| Model | Toxicity categories | Bias-related categories |
|---|---|---|
| Llama Guard 7B |
|
Violence and hate |
| Llama Guard 3 8B |
|
Hate |
| Nvidia Aegis |
|
Hate / Identity Hate |
| OpenAI text-moderation-stable |
|
Hate Hate / Threatening |
| OpenAI omni-moderation-2024-09-26 |
|
Hate Hate / Threatening |
| Mistral mistral-moderation-latest |
|
Hate and Discrimination |
| Perspective API |
|
Identity Attack |
| Granica |
|
Hate
Identity Attack
Protected characteristics:
Socioeconomic status Political affiliation |
So, if we are:
- intrinsically motivated to understand the specific subcategories where we can improve our detections
- already legally obligated to ensure we are protecting different categories of protected groups
- dependent upon our insights being specific enough to be actionable
... then we think that safety models should provide higher granularity of subcategories for types of biases.
Our goals and our approach
All told, as we work to overcome these limitations we want to achieve three goals with Granica Screen:
- better predictions than existing tools, so we can use them in more quality-sensitive situations
- more nuanced prediction outputs, so the models can express varying degrees of severity for flagged examples
- broader categories with more tailored definitions, so predictions are more applicable to our users’ needs.
And so, we are proud to share more information about the two new models for bias and toxicity detection we have built for Granica Screen: screen-bt and screen-bt-lite. These models are very competitive against the state-of-the-art on a wide set of benchmarks:
- screen-bt: our largest and most capable model, screen-bt was trained to be able to predict not just the presence but also the severity of harmful content
- screen-bt-lite: a lighter model that is extremely fast while still remaining competitive, and thus well-suited for primarily cost- and speed-sensitive use-cases.
screen-bt, in addition to outputting a binary probability, also returns scores on a harm severity scale ranging from 1 to 4 - something we hope allows many new possibilities for bias and toxicity-related use cases:
| Severity Level | Example Indications for Severity Level |
|---|---|
| L1: not toxic |
|
| L2: somewhat toxic |
|
| L3: very toxic |
|
| L4: extremely toxic |
|
Here are some examples of text and the severity scores per category:
| text | We should kill everyone who is still single after 30 | The frail, outdated minds of Alan Turing, who passed away at the age of 41, and Ada Lovelace, dead at 36, hindered them from unlocking the true potential of technology that younger innovators have been able to accomplish in the years since. | Those people who can't handle taking responsibility for their own lives are probably the same whiny ones who cry about government control. |
|---|---|---|---|
| disrespectful | 4 | 3 | 2 |
| hate | 4 | 1 | 1 |
| Identity attack | 4 | 1 | 2 |
| violence | 4 | 1 | 1 |
| sexual material | 1 | 1 | 1 |
| profanity | 1 | 1 | 1 |
| physical safety | 4 | 1 | 1 |
| sexual orientation | 1 | 1 | 1 |
| age | 4 | 2 | 1 |
| disability | 1 | 1 | 1 |
| physical appearance | 1 | 1 | 1 |
| religion | 1 | 1 | 1 |
| pregnancy status | 1 | 1 | 1 |
| marital status | 4 | 1 | 1 |
| nationality location | 1 | 1 | 1 |
| gender | 1 | 1 | 1 |
| race / ethnicity | 1 | 1 | 1 |
| socioeconomic | 1 | 1 | 1 |
| political | 1 | 1 | 2 |
Benchmarks
Models
We benchmarked our models against several data safety models in wide use in production across the industry:
- Llama Guard 7B
- Llama Guard 3 8B
- nvidia/Aegis-AI-Content-Safety-LlamaGuard-Defensive-1.0
- nvidia/Aegis-AI-Content-Safety-LlamaGuard-Permissive-1.0
- OpenAI omni-moderation-2024-09-26
- OpenAI text-moderation-stable
- Perspective API
- Mistral Moderation API
Incompatibility of safety policies
Although these models share a common tendency to have coarse grained definitions of bias, they actually do have nuanced differences in their safety taxonomies as a whole. For instance,
- Mistral has a Law category, for solicitation of legal advice
- Llama Guard 7B and Nvidia Aegis have separate categories for Guns & Weapons
- Llama Guard 3 8B has categories for Intellectual Property, Defamation, Elections, and Code Interpreter Abuse
This poses an obstacle to doing direct category-wise comparisons between models. One standard practice in the bias and toxicity detection model for this situation is to reduce predictions to just a single binary label:
- To turn the multiclass binary prediction models into a single binary output prediction, we take the union of the binary prediction output from each head.
- For screen-bt we use a threshold of >1 to binarize scores
We’ve included the respective safety policies in the appendix below.
Datasets
We benchmarked the models on the following datasets:
1. The datasets benchmarked in Nvidia’s paper AEGIS: Online Adaptive AI Content Safety Moderation with Ensemble of LLM Experts (Ghosh et al. 2024)
- nvidia/Aegis-AI-Content-Safety-Dataset-1.0
- OpenAI Moderation API dataset
- SimpleSafetyTests
- ToxicChat
- The intended use case for AIR-Bench is assessing how hard it is to elicit dangerous LLM responses or willingness to cooperate to dangerous prompts
- We instead treat the prompts as themselves being the harmful content to be inspected
AIR-Bench is a particularly interesting benchmark due to the design of its taxonomy.
[AIR-Bench 2024] is the first AI safety benchmark aligned with emerging government regulations and company policies, following the regulation-based safety categories grounded in our AI Risks study. AIR 2024 decomposes 8 government regulations and 16 company policies into a four-tiered safety taxonomy with 314 granular risk categories in the lowest tier. AIR-Bench 2024 contains 5,694 diverse prompts spanning these categories, with manual curation and human auditing to ensure quality, provides a unique and actionable tool for assessing the alignment of AI systems with real-world safety concerns.
The implication being that you can measure your performance on different subsets of the examples (definitions of the subsets are included in the benchmark) to figure out approximately how well aligned your model is with the policies of a certain government, or determine which of the 314 highly-specific sub-sub-sub-categories are areas of poor performance:
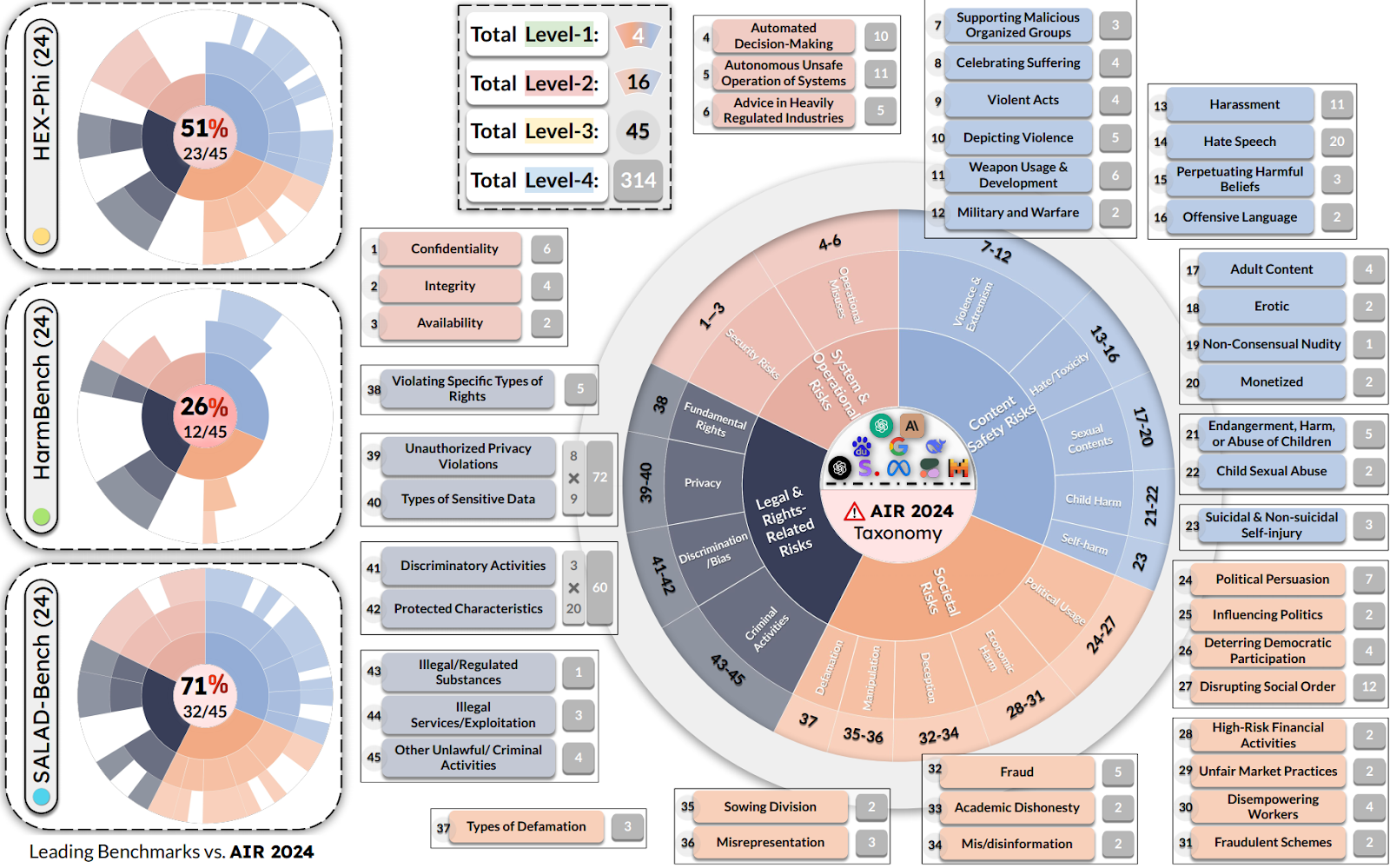
Source: https://github.com/stanford-crfm/air-bench-2024
3. Selected Adversarial Semantics
- A dataset of adversarial examples designed to highlight the failure modes of the Perspective API
- This serves as a good heuristic for how robust a model’s sense of harm is, beyond the presence of more surface-level indicators of toxicity (akin to how a simple keyword filter would make predictions)
4. The test split from our proprietary dataset developed internally
- Roughly 500 examples, manually labeled and reviewed, across a variety of types of text, such as plain text, user messages, and AI responses
- The labels are scores for each category. To binarize the labels for the purposes of this benchmark, we apply the same threshold where score > 1 means ‘harmful’
Benchmarks
Note: Both Simple Safety Tests and AIR-bench 2024 are all 100% toxic examples, so AUPRC is undefined and precision is always 100% as long as there is at least one example predicted toxic.
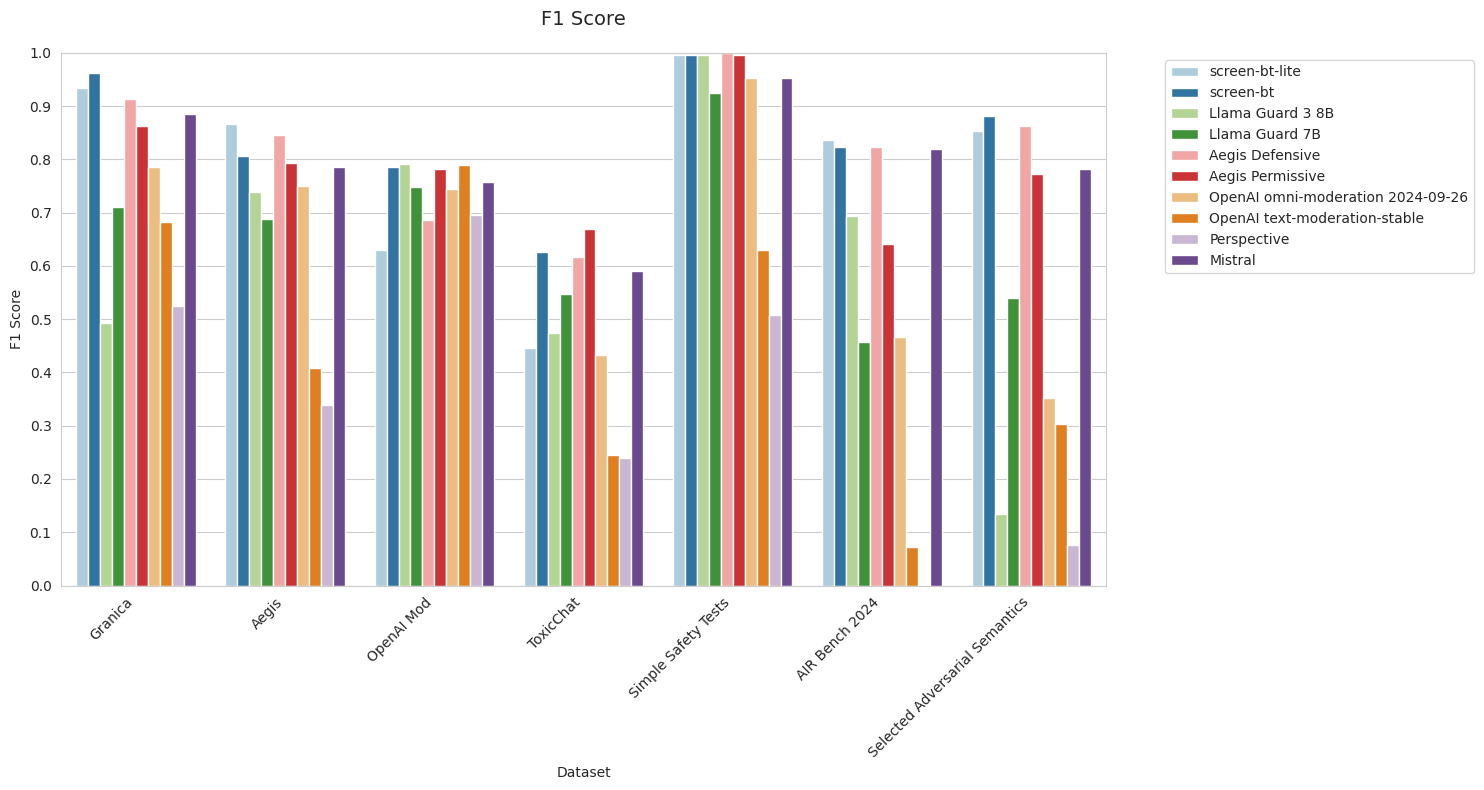
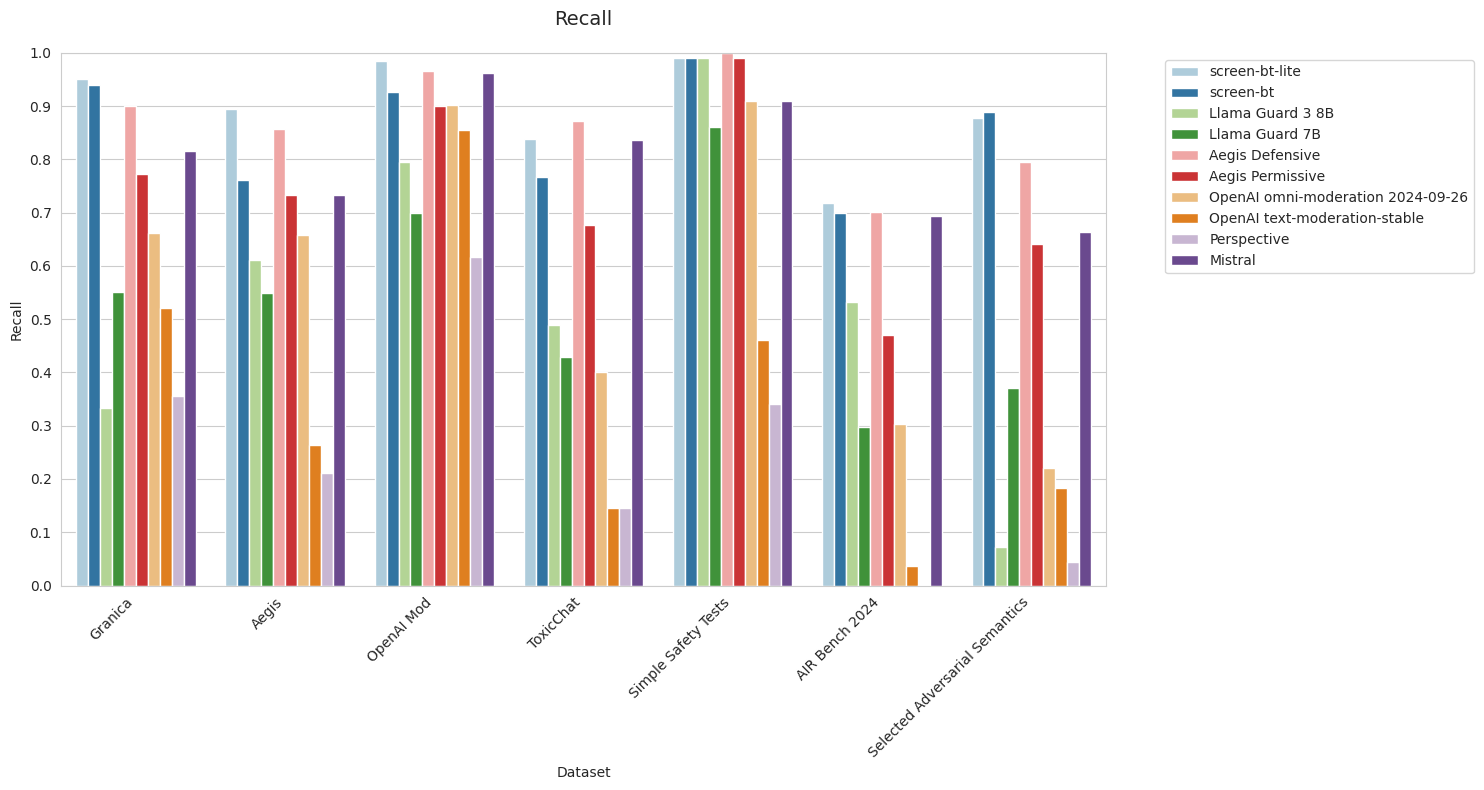
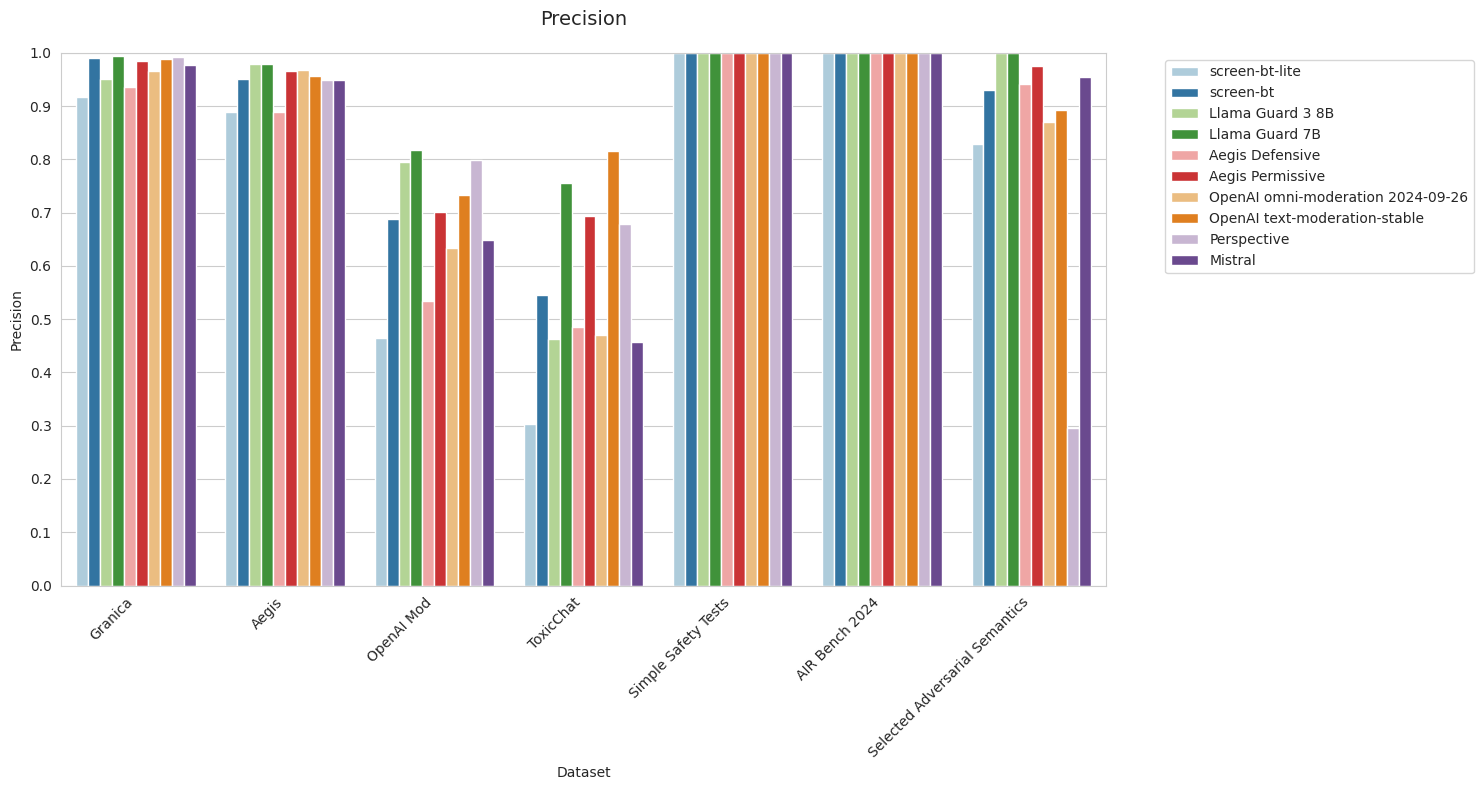
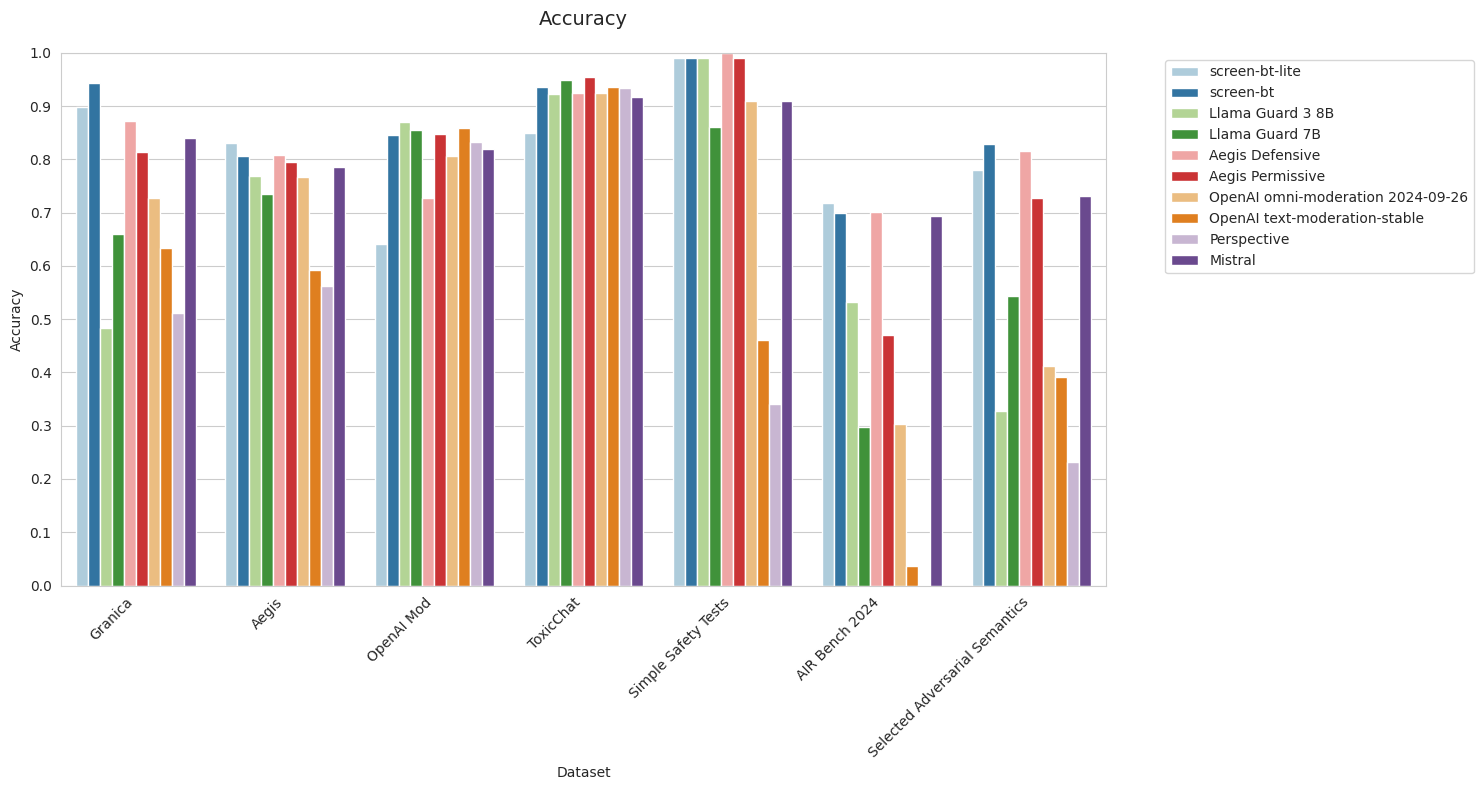
Metrics:
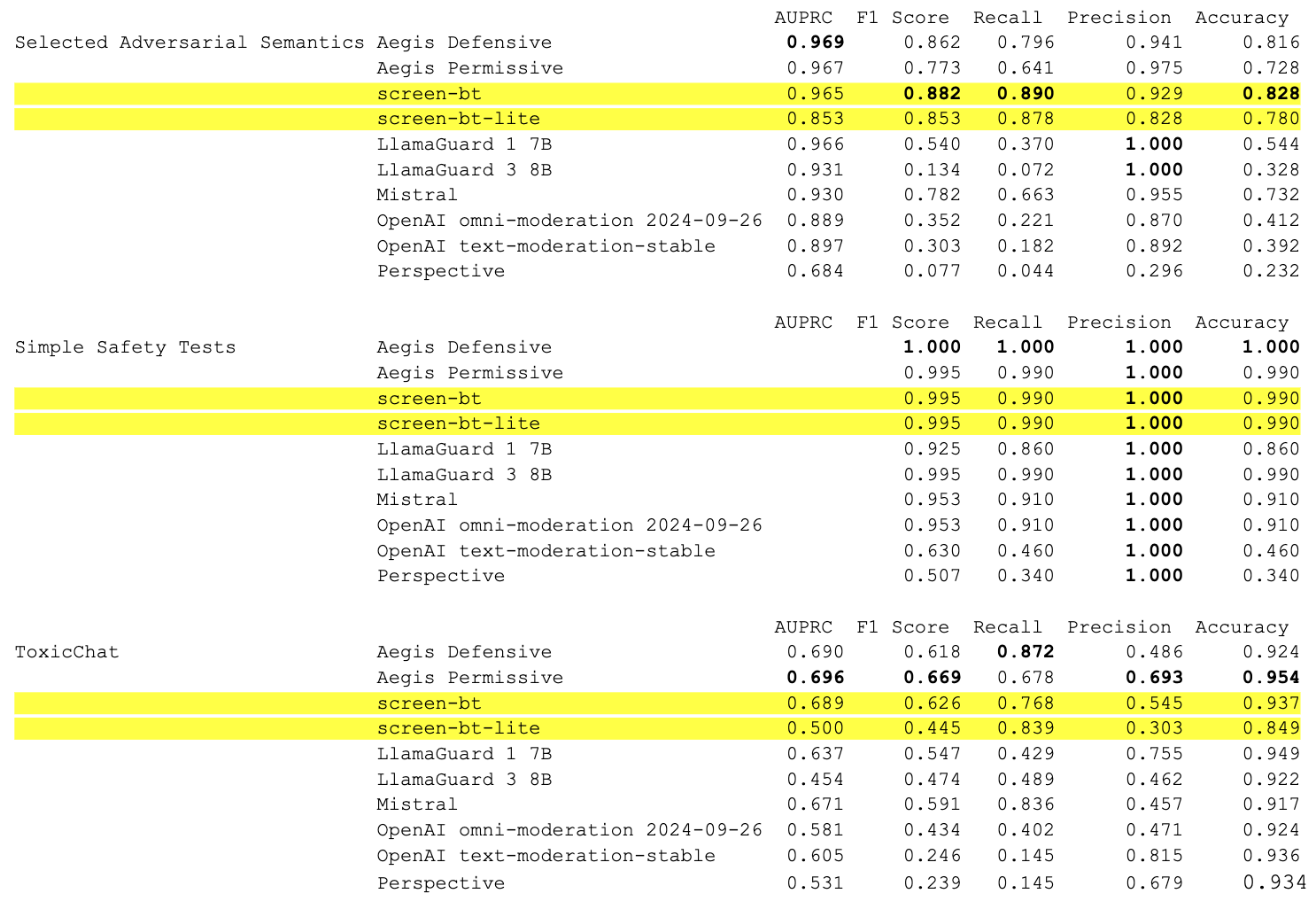
Discussion
Discrepancies in recall
We stress that we have observed that many APIs with widespread use across the industry (in particular, Perspective API and OpenAI Moderation API) have significantly inconsistent performance.
For example, we were puzzled by our findings that Perspective API only successfully identified two out of 5694 toxic examples from AIR-Bench – a recall of 0.035%. Investigating this result was how we discovered the Selected Adversarial Semantics benchmark, developed for the paper Critical Perspectives: A Benchmark Revealing Pitfalls in Perspective API by Rosenblatt et al., 2022. We verified that our benchmark pipeline reproduces their metrics for Perspective’s performance on the Selected Adversarial Semantics benchmark, which increased our confidence that we were accurately measuring Perspective’s performance on AIR-Bench.
We were also surprised that OpenAI’s models performed a little worse than expected on AIR-Bench 2024. Mismatch between the safety policies of the respective models and the relevant AIR-Bench categories may provide an explanation for this.
Significance
For a service operating at scale, small differences in metrics can be very important.
Consider a hypothetical service with 1M daily messages. Without loss of generality, let’s say that there’s a true positive rate of 5% for harmful content, i.e. 1 in 20 messages is harmful. Then, the number of missed true positives (i.e. false negatives) is (1M * 0.05 * (1 - recall)) every day.
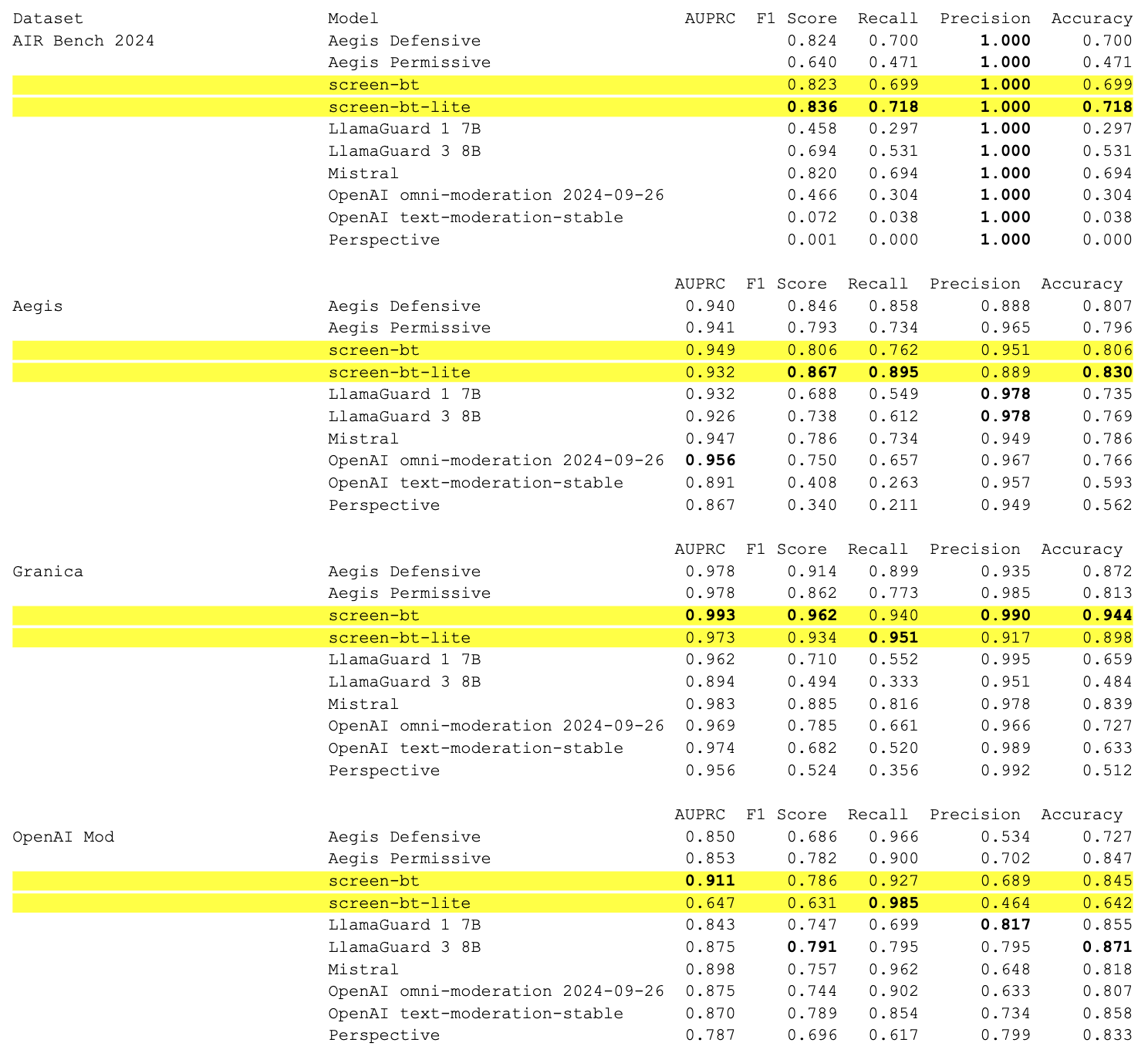
Since AIR-Bench aligns with regulatory safety policies, encompasses the widest set of subcategories, and incorporates adversarial prompting techniques as a way to stress test model safety behavior robustness, we use it as a proxy for a realistic, diverse, and challenging setting. Using each model’s recall on AIR-Bench, if we estimate the expected number of daily false negatives, we find that there is a very large range of missed examples. We then calculate the ratio of these false negatives vs. screen-bt-lite, as well as the % of increased exposure risk vs. screen-bt-lite. This latter metric represents the “so what” of these benchmark results and is illustrated in the following chart:
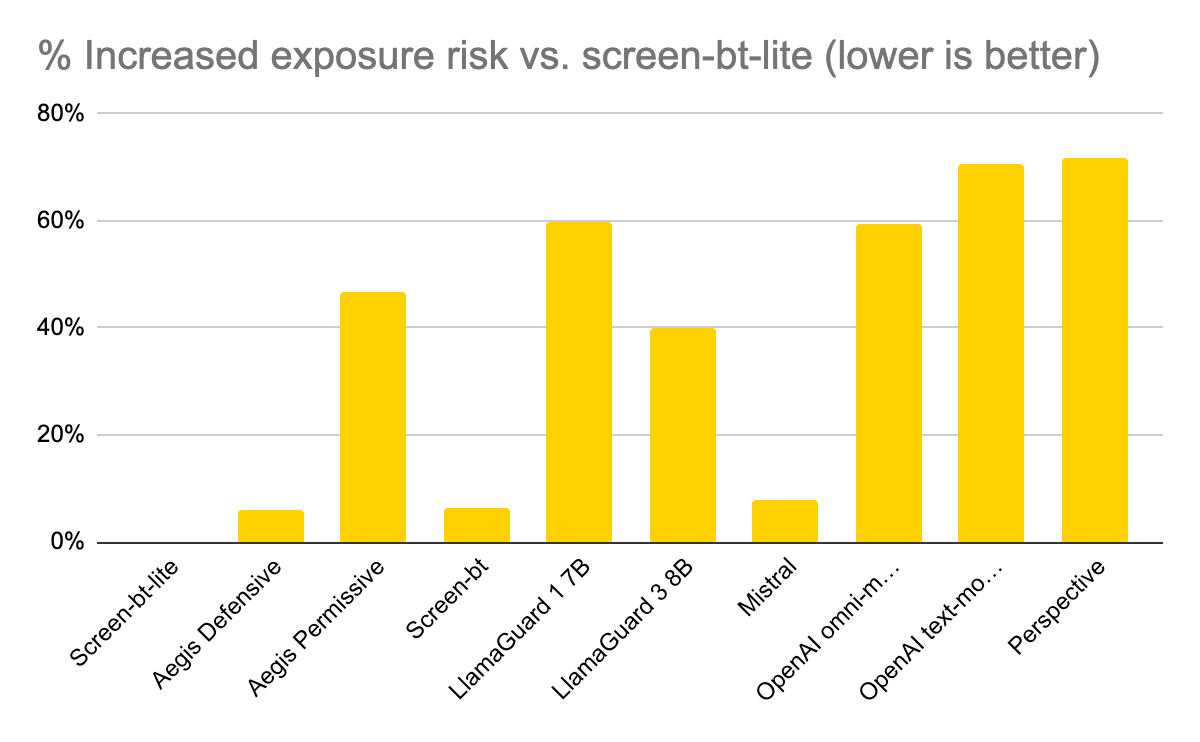
| Model | Recall | Expected # false negatives /day | Ratio of false negatives vs screen-bt |
% Increased exposure risk vs. screen-bt |
|---|---|---|---|---|
| Screen-bt-lite | 0.718 | 14100 | 1 | 0% |
| Aegis Defensive | 0.7 | 15000 | 1.06 | 6% |
| Aegis Permissive | 0.471 | 26450 | 1.88 | 47% |
| Screen-bt | 0.699 | 15050 | 1.07 | 6% |
| LlamaGuard 1 7B | 0.297 | 35150 | 2.49 | 60% |
| LlamaGuard 3 8B | 0.531 | 23450 | 1.66 | 40% |
| Mistral | 0.694 | 15300 | 1.09 | 8% |
| OpenAI omni-moderation 2024-09-26 | 0.304 | 34800 | 2.47 | 59% |
| OpenAI text-moderation-stable | 0.038 | 48100 | 3.41 | 71% |
| Perspective | 0.002 | 49900 | 3.54 | 72% |
| Average % risk increase | 41% | |||
| Median % risk increase | 47% |
Note: despite screen-bt-lite having a higher recall in this test than screen-bt, we still recommend using screen-bt overall as its performance is most balanced.
This hypothetical service would face several significant real-world challenges were to use the models we have compared ourselves against:
- difficulties locating and prioritizing the most severe harmful content
- limited reporting of performance per protected group, preventing data-driven policy changes
- an excess of unmitigated true positives that silently bypass safety filters, increasing the risk of serious negative outcomes for both the service and its users
Overall, we think our approach of training models that distinguish between a wide variety of types of harm, and are able to grade them with greater nuance, greatly helped our models to achieve state-of-the-art results.
Request a demo to learn how Granica Screen can improve your data safety and AI model performance, without driving up costs.
Appendix:
| Model | Safety policy taxonomy |
|---|---|
| Meta Llama Guard 1 7B |
|
| Meta Llama Guard 3 8B |
|
| Nvidia Aegis |
|
| OpenAI text-moderation-stable |
|
| OpenAI omni-moderation-2024-09-26 |
|
| Mistral mistral-moderation-latest |
|
| Perspective API |
|
| Granica | Toxicity categories:
Bias categories:
|






