Over the past decade, cloud-based data lakes and data lake storage, particularly on Amazon S3, have become the foundation for storing and processing massive amounts of data. Their scalability, cost-efficiency, and ability to support a wide variety of analytics and machine learning workloads make them indispensable for data-driven organizations.
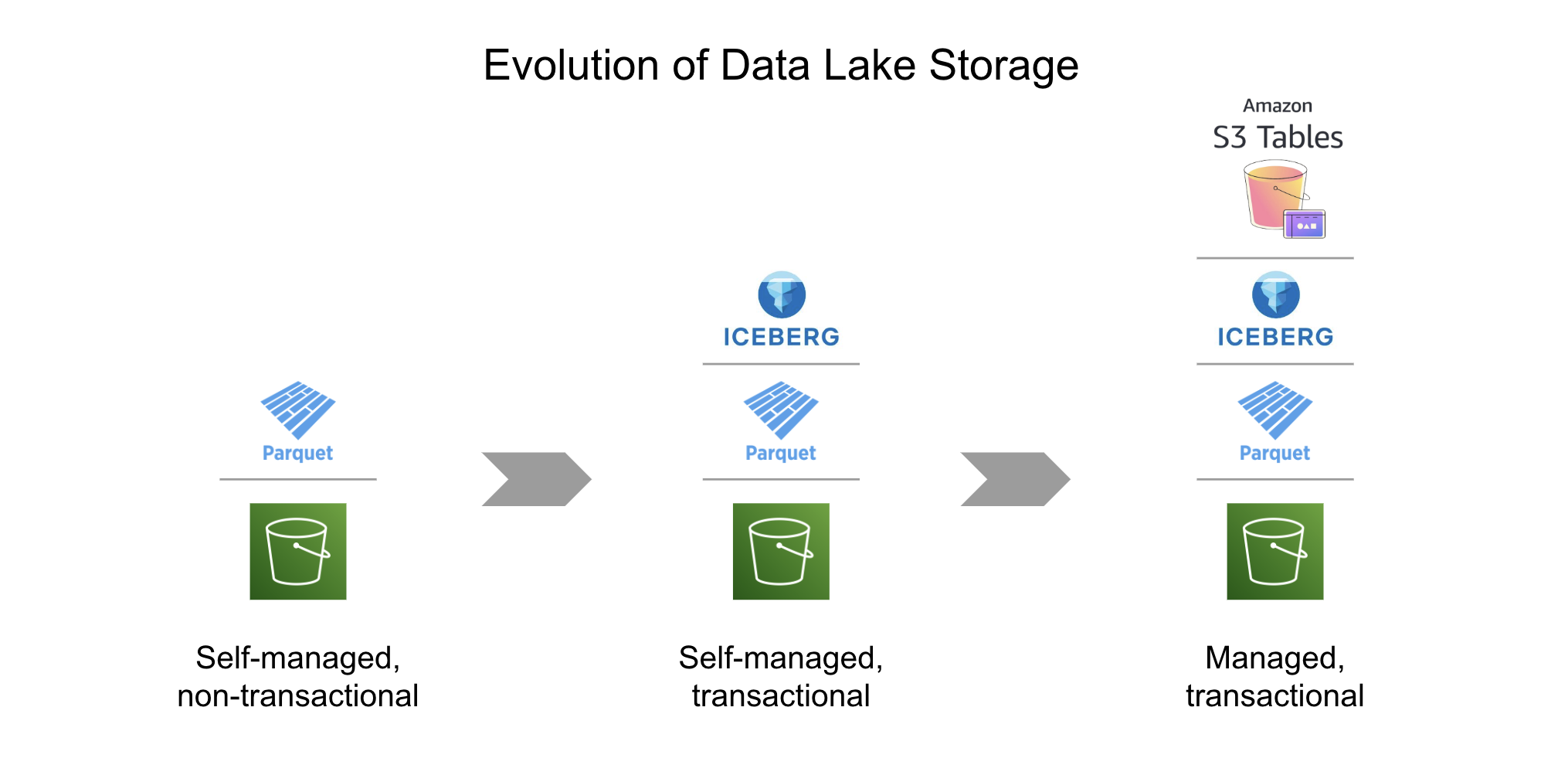
However, as data teams pushed the limits of what data lakes could do, a significant gap emerged: transactional capabilities like those found in data warehouses. For companies needing ACID-compliant reads and writes, many turned to open table formats such as Apache Iceberg and Delta Lake to introduce data warehouse-like transactionality to their data lakes, effectively transforming them into data lakehouses. While Iceberg has been a game-changer, adopting it in a self-managed environment has proven challenging.
Organizations managing Iceberg-based data lakehouses on their own face several hurdles:
- Operational Complexity: Manually handling compaction, file pruning, and metadata management requires considerable time and expertise.
- Performance Issues: Suboptimal file structures and small-file proliferation can degrade query performance, impacting analytics and machine learning workloads.
- Resource Drain: Data engineers often spend countless hours tuning and maintaining the environment, diverting time away from high-value initiatives.
These challenges make it clear that while self-managed data lakehouses can deliver performance and consistency, they come at a steep operational cost.
In this blog, we explore how the recently announced Amazon S3 Tables is poised to transform Iceberg-based data lakehouses, why its use of Apache Parquet matters for performance, and how solutions like Granica Crunch can further enhance cost efficiency and query speeds.
Amazon S3 Tables in a nutshell
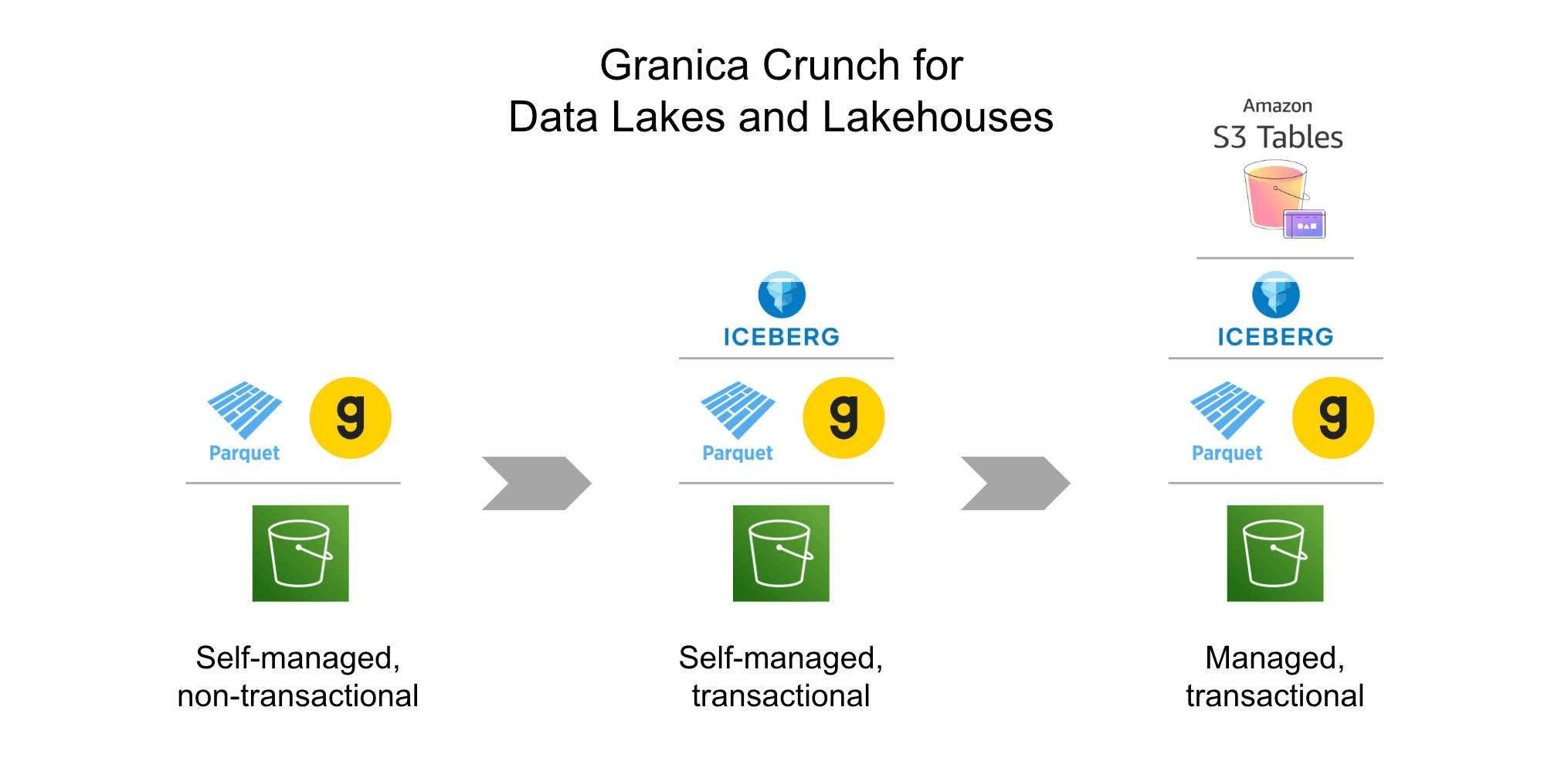
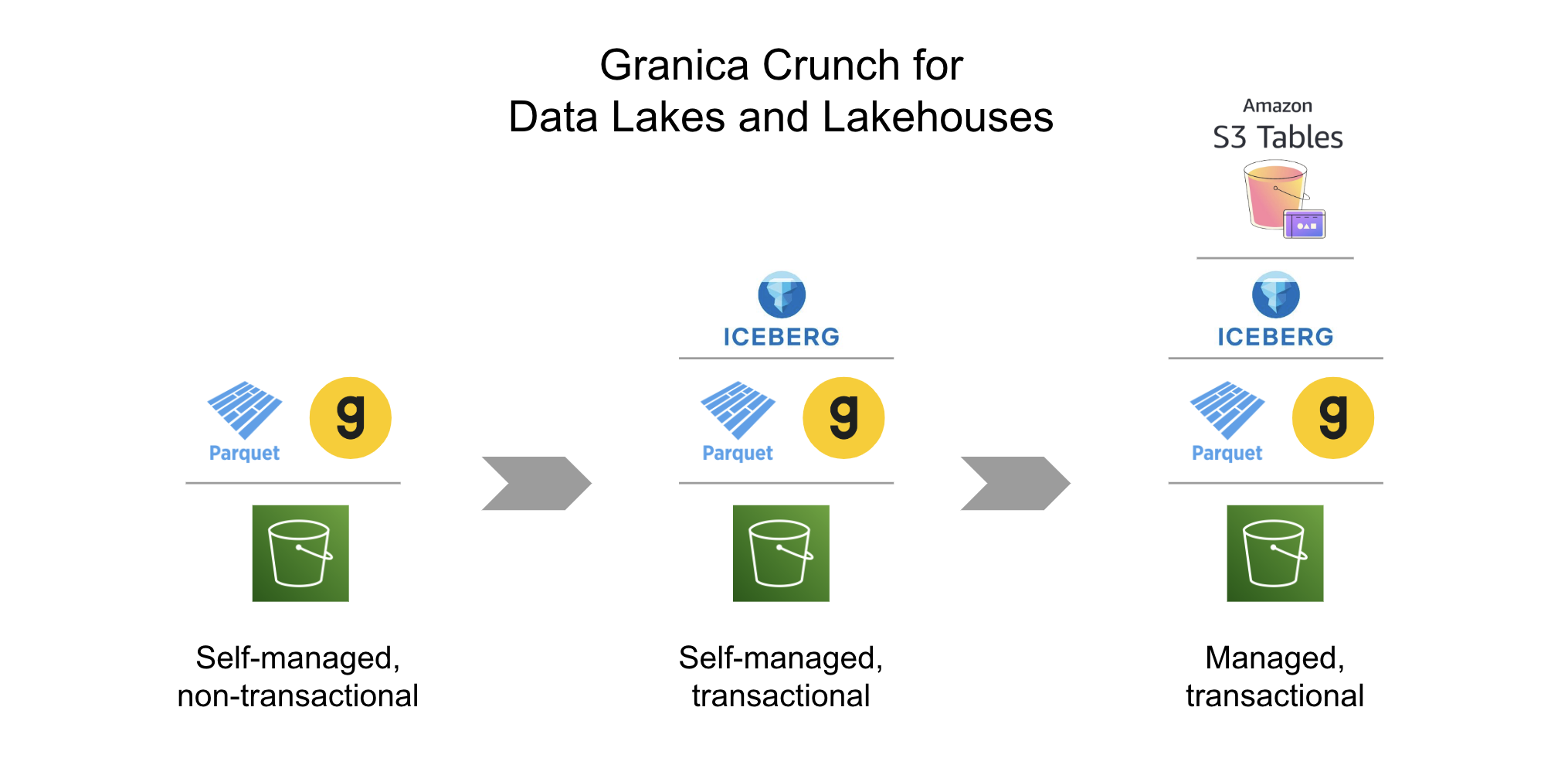
Amazon S3 Tables is a fully managed solution that combines the scalability and flexibility of object storage with the transactionality and performance enhancements of Iceberg. At its core, S3 Tables builds on open data lake standards, particularly the widely adopted Apache Parquet format. Parquet is a columnar file format that is highly efficient for both storage and query performance, making it ideal for large-scale analytics workloads.
What sets S3 Tables apart is its ability to simplify transactional workloads. It natively supports the Iceberg table format, which brings ACID transactions to S3 and Parquet-backed data lakes. This means data teams can enjoy consistent, reliable reads and writes without the need for complicated manual configurations.
Why S3 Tables is a game changer for data lakes
Amazon S3 Tables delivers improved performance, scalability, and consistency, helping address long-standing challenges while enabling data teams to maximize the value of their cloud-based data lakes. Here’s why S3 Tables stands out:
Improved performance for analytics workloads
One of the most significant challenges of traditional data lakes is query performance. As data grows, particularly in environments with frequent incremental writes, small-file proliferation becomes a major bottleneck. Query engines must scan through an excessive number of files, leading to slower response times and increased computational costs.
S3 Tables addresses this issue with automatic file compaction. By consolidating small Parquet files into larger ones, S3 Tables reduces the overhead of file scans thus speeding up read throughput and ultimately query speeds by up to 3x. Unlike self-managed environments where engineers must manually implement and tune compaction, S3 Tables automates this process entirely, ensuring performance gains with minimal effort.
For data teams, this translates into:
- Faster query results, enabling quicker insights for decision-making.
- Reduced compute costs, as query engines perform fewer, more efficient scans.
- Less time spent managing and optimizing file structures manually.
Scalability and flexibility
Scalability has always been one of Amazon S3’s greatest strengths, and S3 Tables builds on this foundation. By leveraging the Apache Parquet format, S3 Tables enables efficient storage that is ideal for analytical workloads. The columnar nature of Parquet allows query engines to scan only the specific columns required, reducing I/O and improving performance.
Parquet also supports compression to further reduce the S3 storage footprint, associated storage cost, and read I/O. Optimizing the compression of Parquet holds great potential but is extremely challenging at scale and thus data teams largely use basic Snappy compression. Later in this blog we’ll outline how Granica is advancing the state of the art of compression optimization to maximize lakehouse efficiency.
In addition to Parquet, S3 Tables are built on the Iceberg table format, adding the critical transactional capabilities needed for complex data operations. This combination supports a wide range of use cases, including batch and streaming data ingestion, interactive queries for BI dashboards, and machine learning model training.
S3 Tables seamlessly integrates with tools like Amazon Athena, Apache Spark, and Presto, eliminating the need to re-architect workflows or invest in new technologies. This makes S3 Tables a natural choice for scaling operations.
Simplified transactional data management
Data lakehouses promise the best of both worlds: the scalability and cost-efficiency of data lakes combined with the transactional consistency traditionally found in data warehouses. However, achieving this balance in a self-managed environment has historically been challenging.
Organizations using Apache Iceberg in self-managed setups face hurdles like:
- Metadata Management: Tracking and maintaining large metadata files requires manual effort to avoid performance degradation.
- File Pruning and Optimization: Without automated pruning, query engines waste time scanning irrelevant files.
- Compaction: Data engineers must manually implement compaction processes to address small-file issues, adding operational overhead.
S3 Tables automates these tasks, ensuring that data remains clean, efficient, and optimized for performance. This eliminates the need for manual tuning, freeing data teams to focus on higher-value initiatives like building models, refining analytics pipelines, and delivering insights.
Why it’s a game changer
By improving query performance, providing seamless scalability, and simplifying transactional data management, S3 Tables removes the operational burdens of self-managed lakehouse environments. Organizations no longer need to choose between performance and simplicity; S3 Tables delivers both.
For data teams, this means faster, more efficient analytics, scalable data lakehouses requiring minimal operational effort, and flexible integration with existing tools and workflows. This managed approach allows teams to focus on using data to drive innovation rather than managing infrastructure.
The hidden efficiency challenges of S3 Tables
While we’re excited by the introduction of Amazon S3 Tables and its transformative capabilities, some underlying challenges persist, particularly around storage costs, query optimization, and operational complexity. Understanding these issues is crucial for data teams seeking to maximize the value of their data lakehouses.
Rising storage costs
Although the columnar Parquet format helps reduce storage footprints compared to traditional row-based formats, as data volumes continue to grow exponentially storage costs in S3 can still spiral out of control.
In addition, transactional workloads often require frequent writes, updates, and inserts, which can lead to an accumulation of redundant data and unoptimized file structures. Even with S3 Tables’ native compaction, the scale of modern data lakes means that storage waste remains a concern. Organizations that rely heavily on transactional systems may find themselves facing escalating cloud bills, particularly as data needs expand well into the 10s (and 100s) of petabytes range.
Without additional strategies to optimize Parquet compression and eliminate unnecessary data, storage costs can escalate rapidly and impact infrastructure budgets.
Query performance gaps
S3 Tables’ automatic compaction addresses small-file inefficiencies but doesn’t fully solve all query performance challenges. Even compacted Parquet files can contain redundant or bloated data, which slows down queries by reducing the throughput of I/O operations as data is read from S3. Query engines must still scan large amounts of unnecessary data, consuming valuable compute resources and driving up costs. This issue is compounded in analytics-heavy environments, where frequent queries across massive datasets are the norm.
Moreover, as datasets become more complex—incorporating semi-structured or nested data—performance tuning becomes even more critical. Without additional compression-related optimizations, organizations may not realize the full performance potential of S3 Tables, leading to slower queries and higher compute costs.
Operational complexity remains
While S3 Tables significantly reduces the operational burden of managing data lakehouses, especially with respect to compaction, it doesn’t address compression. Parquet supports multiple open source compression algorithms (e.g. Snappy, Zstandard, Gzip) and encoding techniques (e.g. RLE, Dictionary, Delta) with a range of trade-offs between compression ratio and performance. Snappy for example has a low compression ratio but is fast and lightweight.
Manually implementing, optimizing and tuning these compression and encoding options for Parquet is a nuanced, resource-intensive process with numerous challenges:
- Selecting the best compression and encoding combinations for different data types and columns requires deep expertise and extensive trial-and-error.
- Data characteristics evolve, and scaling optimization efforts across large, heterogeneous datasets or distributed systems is resource-intensive.
- Engineers must navigate the trade-offs between storage costs, query performance, and processing overhead, which can be difficult without proper insights.
- Manually implementing, managing, and tracking the effectiveness of compression and encoding settings adds complexity to workflows.
As a result of these challenges most data lake platforms including S3 Tables simply leverage Snappy compression in a one-size-fits-all manner, leaving unrealized and untapped efficiency potential, both for reducing costs and for improving query performance.
How Granica Crunch complements S3 Tables
The challenges of storage costs, query optimization, and operational complexity reveal that while S3 Tables simplifies the transactional data lake experience, it doesn’t fully address the needs of large-scale data environments. To truly unlock the potential of S3 Tables, organizations need complementary solutions.
This is where Granica Crunch comes into play. Today, Crunch provides an additional layer of optimization for self-managed Parquet data in S3, working seamlessly with open-source Apache Spark and Amazon EMR. It delivers advanced compression optimization for Parquet, reducing storage costs, minimizing I/O, and improving query performance.
TPC-DS benchmarks show Crunch can:
- Reduce the physical size of pre-compressed Parquet files by 15-60%, lowering storage costs and data transfer times.
- Speed queries by 2-56%, enhancing analytical responsiveness and driving productivity for data engineering teams and downstream BI, AI, and ML workloads.
- Shorten AI/ML model training cycles and reduce compute costs, delivering significant benefits for large training datasets.
Looking ahead, Crunch support for Amazon S3 Tables, self-managed Iceberg tables, and Delta Tables is on the roadmap, with delivery expected early next year. By addressing the efficiency challenges of data lakes and (soon) data lakehouses, Crunch enables organizations to achieve better performance, lower costs, and greater operational efficiency.
Learn how Granica Crunch can help optimize your existing data lake today and your S3 Tables-based data lakehouse in the near future.